人文情報学月報第141号【前編】
目次
【前編】
- 《巻頭言》「国会図書館デジタルコレクションがつなぐエジプトと日本、そしてリン鉱石」
:慶應義塾大学経済学部 - 《連載》「Digital Japanese Studies
寸見」第97回
「なぜ標準化は退屈で重要なのか: ふりがな要素の TEI P5 導入議論の経験から」
:慶應義塾大学文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第58回
「対話型 AI を用いた言語データの構造化のためのプロンプトエンジニアリング」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第15回
「デジタル・ヒストリーにおける研究過程論(1):科学哲学史の議論をきっかけに」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第6回
「ADARSHAH」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「国会図書館デジタルコレクションがつなぐエジプトと日本、そしてリン鉱石」
2022年12月某日、エジプト紅海沿岸の港町クセイル。私は海沿いに佇む寂れた工場跡地にいる。地元の人から、ここがかつてリン鉱石の工場だったことを聞いていた。その奥に見える立派な教会に惹かれ、工場の敷地内に足を踏み入れた。幸い、不審なアジア人の侵入を咎める者は誰もいない。教会に至る道には人の気配はなく、あたりはしんと静まりかえっている。両脇には、かつての作業場がほとんどそのままの形で残されている。その一角には、走り書きのアラビア文字や1990年代の日付が書き込まれたおびただしい量の領収書の束がうち捨てられていた。工場のメインストリートの終点まで辿り着き、教会の門をくぐる。この聖処女マリアと聖女バルバラ教会は、20世紀初頭にこの工場で働いていたイタリア人によって建てられたものだという。領収書の束、イタリア人が建てたという教会、あたりに転がっているリン鉱石とおぼしき物体、おそらくそれらを運ぶために敷設されたと思われる線路跡、ドックのような構造物…これまで目に留まったもの一つ一つの情報が未知のものだ。それらは整理されないまま、分子になれない原子のように、頭の中を浮遊している。

敷地入口付近にあった小さな建物外壁に、手書きで「MUSEUM」の文字が書かれていたことを思い出し、立ち寄ることにした。その最初の小部屋に入ると、管理人らしき男性が現れた。彼に頼んで事務室に案内してもらい、話を聞くことにした。そして、イタリア人がリン鉱石の加工と輸出のために建てた工場だったことや、第二次世界大戦後に国営化されたことなどがわかった。先ほどまで頭の中を個別に浮遊していた情報が次々と結びついていく。その話を聞きながら事務室の年季の入った壁に目を遣ると、大判の世界地図が掛けられている。ただの地図ではない。そこには矢印がいくつも描かれている。どうもネットワーク図のようだ。紫色の矢印の起点はクセイル、その終点はイタリアと…日本…?
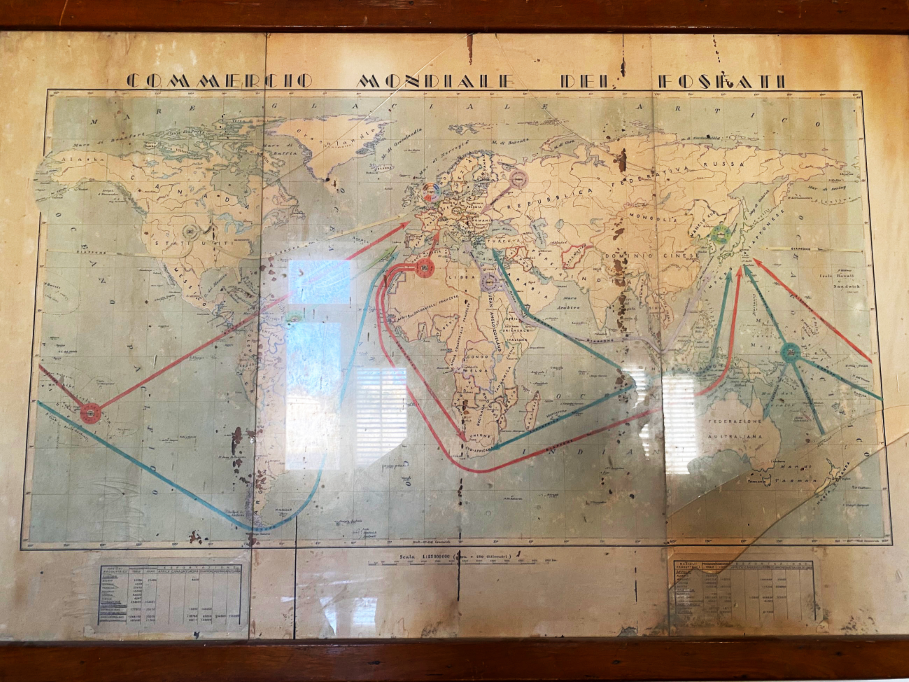
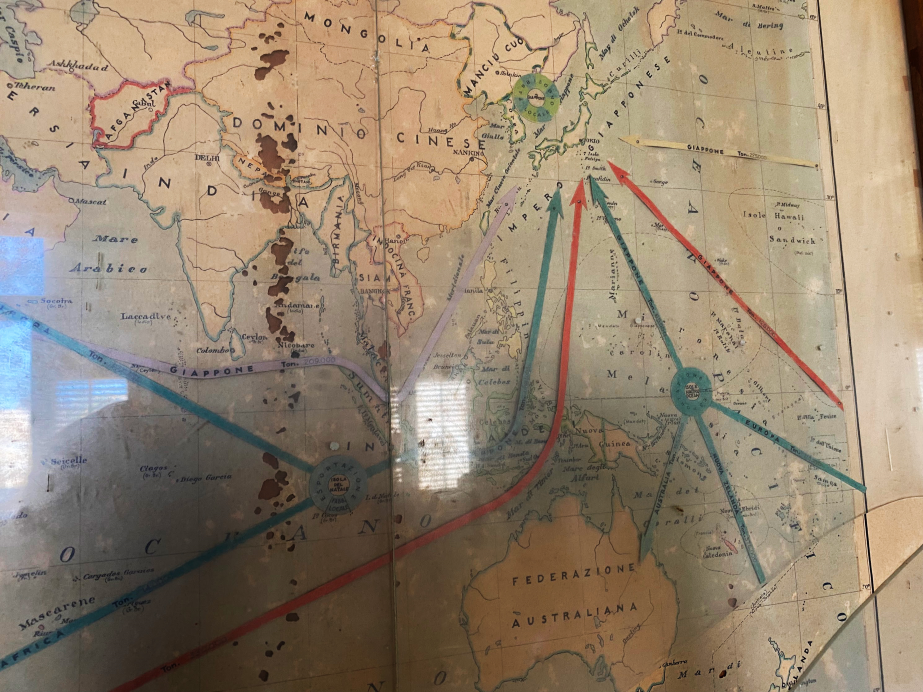
目を疑いながらも世界地図に近付き、矢印が向かう方向が確かに日本であることを確認する。地図の上部には、「Commercio Mondiale dei Fosfati (リン鉱石の世界貿易)」と書かれている。この瞬間、雷に打たれたような衝撃を受けた。このクセイルという紅海沿岸の寂れた港町で、イタリアとエジプト、日本の歴史が、リン鉱石交易によって結びつけられた瞬間だった。
帰国後、国会図書館デジタルコレクションで、「埃及」「燐鉱石」などの検索語で資料を検索し、手当たり次第目を通していった。『埃及経済事情と日埃貿易』(1928)には、「埃及輸出上に於ける日本の地位」という項目で「埃及燐鉱石は、コシア産、サファガ産を主要とす」とあり、「燐鉱石の産額逐年漸増の趨勢にある今日、埃及燐鉱石と日本とは極めて密接なる関係を有す」と締めくくられていた[1]。「コシア」と書かれている聞き慣れない地名は、クセイル(Qoseir)が日本語風になまったものなのだと理解できた。そこで今度は「コシア」という語を検索し、ヒットした資料を一つずつ確認していった。かくして、私は大戦間期に日本とエジプト、そしてイタリアのあいだに展開したリン鉱石交易の研究にのめり込んでいったのだった。
私のことを知る人たちは、私が今このようなテーマを追っていると聞いたらさぞ驚くだろう。何を隠そう、私の専門は13世紀~16世紀のナイル灌漑と土地制度研究。これまでの研究で近現代の日本側の史料を扱ったことなど一度もない。本来ならば、史料にアクセスすることもできないまま、上記の話も、酒の席で披露するミステリアスなトリビア程度で終わっていただろう。しかし、国会図書館デジタルコレクションの全文検索は、フィールドで集められたバラバラな情報をつなぎ合わせ、歴史研究としての叙述に変化させる原動力を与えてくれる。
幸運にも、私がちょうどエジプト産リン鉱石について調べ始めた2022年12月というのは、国会図書館デジタルコレクションが大幅にリニューアルされた時期であった。このとき、全文検索可能なデジタル化資料が5万点から247万点に増加した。また、画像検索機能も追加され、内容面と機能面で飛躍的な拡充がなされた[2]。これにより、同年5月からはじまっていた個人向けデジタル化資料送信サービスの範囲も広がり、自宅にいながら入手が難しい資料を読むことがより容易かつ効率的になった[3]。こうした国会図書館デジタルコレクションの大幅なアップデートには、2019年からはじまったコロナ禍の影響がその背景にある。しかし、ここで私が強調したいのは、同コレクションの発展は、単に私たちの日常の生活様式の変化に対応したのだとか、前よりも便利になったのだということではなく、デジタルコレクションの存在自体が、研究や専門といった「敷居」を下げ、はじめの一歩を踏み出すための間口を広げているということだ。
その後、私は日本経済史に関する研究書や工具書を積極的に手に取るようになった。同コレクションでヒットしたものだけが資料のすべてではないためだ。インターネット検索だけで研究が完結しないことは以前と変わらない。そこから先はデジタル化されていないものも含め、資料の大海に乗り出す必要がある。そうしているうち、気づけば、日本経済史の専門家と意見交換をする機会も飛躍的に増えた。今まで勝手に遠いと決めつけていた日本とエジプトが、実は接し合い、お互いを不可欠としていたことを初めて知り、自分のなかで何か新しい世界が拓けたような気がしている。
最後に、歴史学徒として、このような国会図書館デジタルコレクションの充実には、歴史学関係団体からの働きかけがあったことも述べておかねばならない。2020年5月23日、コロナ禍において各地の図書館サービスが制限された状況を受け、日本歴史学協会ほか歴史学に関わる29学会・研究会は「国立国会図書館デジタルコレクションの公開範囲拡大による知識情報基盤の充実を求めます」を発表した[4]。同年9月以降、日本歴史学協会は、国立国会図書館と協力しながら、国立国会図書館デジタルコレクションによる歴史学関係団体の学会誌のオープンアクセス化に向けた取り組みを進めてきた。上に見てきた国会図書館デジタルコレクションの拡充は、国会図書館がそのような要望を真摯に受け止め、かつ著作権者側である歴史学関係の学会や協会も、研究成果のオープンアクセス化に向けて働きかけや協力をしてきたことが背景にある[5]。ユーザーとしての恩恵を受けつつ、著作権者として著作権の問題とオープンアクセス化の問題を前向きに検討していくことの重要性についても改めて痛感している。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第97回
「なぜ標準化は退屈で重要なのか: ふりがな要素の TEI P5 導入議論の経験から」
何度目のご報告かと自分でも思うが、この4月から慶應義塾大学文学部に着任した。前職同様、デジタル人文学は主たる職責ではないが、プロジェクトなども主導するような立場にもなってきたので、自分になにができるか考えていきたい。
デジタル人文学は、とはいえ、なんとも摑みどころに困る分野であろうと思う。永崎研宣氏がここ数年来、日本においても強調されるところである、メソドロジカルコモンズ(方法論の共有地)[1]は、この鵺的な学際分野を肯定的に特徴付けたことばであるが、私見を加えれば、人文学のロゴスを重視する側面は、デジタル人文学ととても相性がよく、この側面からの発達はなお限界を迎えるに至っていないと思う。
そのようなロゴス重視は、共通知識基盤をコンピュータ上に作り出す共同体あってこそ成り立つ。たとえば、反 Unicode 論が日本で一時期おおきな流れともなっていたとき、その反欧米的な風潮に流されず、Unicode を実際的なものとするために奮闘された方々によって、日本の戸籍や地名などの字書などにも載りにくい文字文化をコンピュータ上で扱う地盤も築かれたのである[2]。ほかにも、デジタル人文学と関わる研究会のひとつである情報処理学会人文科学とコンピュータ研究会の蓄積ひとつとっても、HuTime[3]やみんなで翻刻[4]など、共有地であることを重視した研究も幅広く行われてきた。
つまり、個別的なことがらを個別特殊のままに進めていくのではなく、人文知探究にひそむ共通基盤を生み出していくのがデジタル人文学の特徴であり、人文既存分野の成果をそこでの文脈を無視して十全には読み解けないように、デジタル人文学においても、そのような特徴を無視してしまっては思ったとおりの成果にも至らないようなことになってしまう。
人文学テキストの標準的記述的符号化手段として欧米を中心にひろく用いられている TEI(Text Encoding Initiative; テキスト符号化イニシアティヴ)もまた、そのような背景を持つものである[5]。TEI は欧米圏だけをターゲットにしてきて非欧米圏の資源には使いがたいという批判が成り立たないことは、近年再確認されるところであるが、とはいえ、東京で開催された TEI の年次会議 TEI2018がはじめて欧米以外の場所で開かれた年次会議であったように、欧米圏の参加者がつよいイニシアチブを持っていることは否定し得ない。TEI は、特定の用途に限定されない、あるていどの一般化されたテキスト符号化を目する枠組みである[6]。そうであるがゆえに、あるいはそうであるがこそ、一般的な記述的マークアップをどれだけ汎文化的に行えるかは、そこの議論にどれだけ多様なひとびとが参画できたかによる。
そのようななかで、稿者らは、TEI にふりがなあるいはルビを記述する要素を提案し、議論を経て採用された。そのときの経緯は別稿にまとめたのでくわしくはそれによられたいが[7]、一般的な記述マークアップを目指してきた TEI において、なぜルビ要素が足りなかったのであろうか。それは、ルビが密接に本文の特定の文字列と結びつくため、既存の書き方では、それを十分に表現することができないからだということを主張した。結果的には、その理由づけが受け入れられたのだと理解している。すくなくとも、東アジアに固有性のたかいテキスト要素の符号化が受け入れられたことは注目すべきことである。
稿者が携わったのはおもに提案書の作成で、その後の議論にはじゅうぶんにくわわれたとは言えないが、一連の議論に参加して、既存の達成に理解を示し、それでもなお不足があることを先行事例によって確認し、そのうえで、可能な解決策を――先行事例が、そのときにあったのであればこれを用いていただろうなというようなものを――模索するのが、このような標準化の過程なのではないかと感じさせられた。これは、じぶんの望むものをただ言えばよい(言っていけないわけではないが)というのとは異なり、だれかのために行うことである。ほかのだれかが、ひとりでもおおく方法論の共有地にアクセスできるようにする試みである。その条件が整っているか、おおくのひととともに確認して進めていくことは、ときとして退屈であり、無限に終わらない感じすらする。しかし、これでだれかが安心してルビのあるテキストを翻刻できるようになるわけで、この点において、重要な営みといってよいと思われる。
デジタル人文学は、急速にひろがりを見せるようになっているが、共有地をどう充実させていけるかはずっと課題であり続けるにちがいない。具体的な規格の標準化というかたちを取るかはともかく、共有されるべき方法論を守り育てるという、一見退屈な仕事を広めていくことは、デジタル人文学が魔法ではないということを知る重要な機会ともなるのだろう。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第58回
「対話型 AI を用いた言語データの構造化のためのプロンプトエンジニアリング」
前回は、OpenAI が公開している対話型テキスト生成 AI アプリである ChatGPT[1]に搭載された新しい大規模言語モデル(LLM)GPT-4の紹介と言語学データへの応用の所感について書いた。2023年4月には、OpenAI の CEO であるサム・アルトマン氏が来日して岸田文雄総理大臣と面会したり[2]、日本の各大学が ChatGPT の使用についてルールや勧告を構成員に送信・告示したりするなど[3]、ChatGPT は非常に大きな話題となっている。
ChatGPT 以外にも、同じように自然言語で入力を行う対話型の生成系人工知能(Generative Artificial Intelligence)の Notion AI[4]などがでてきている。また、ChatGPT のトレーニングプロセスをオープンソースで提供する Colossal-AI[5]も公開された。さらに、Google が Bard[6]を発表し、Amazon も生成系 AI の API サービス Amazon Bedrock と大規模言語モデル Amazon Titan を発表する[7]など、大企業も競争に加わっている。そのほかにも、対話型生成系 AI 同士を対話させて、より良い回答を出す CAMEL[8]など、これらの生成系 AI を駆使したプログラムも多数できている。加えて、GitHub Copilot[9]など、ユーザが欲しいコードの指示を与えることでコードの例を生成しコード作成を支援するシステムや、Catchy[10]のように、ステップバイステップで生成したい文章の内容の指示を書き、ユーザが望む文章を生成するもの、そのほか、ユーザが作りたいスライドの要旨を入力すると、即座に画像入りのスライドを生成していく Tome[11]などの便利なアプリの公開が相次いでいる。その上、Microsoft は、Word や Excel などの Office に Microsoft 365 Copilot[12]を搭載し、ユーザの自然言語による指示で、文書、表計算、スライドの内容やデザインを自動で生成できるようにすることを発表している。
この流れから行くと、上手なプロンプトを書き、これらの生成系 AI にユーザが望む結果を作成させるスキルが、これからより重要になってくるであろう。確かに、ChatGPT などは、特に何も気にせずとも、文法が間違っていたとしても、簡単な指示をプロンプトとして入力したら、問題なく望んでいた出力が返ってくることがある。しかしながら、プロンプトが曖昧、あるいは、複雑であったり、生成する結果が長くなったりするほど、ユーザ側が望まない結果になってしまいがちである。例えば、次の例をみてみよう。

この例では、日本語の文章を、記述言語学や言語類型論でよく使われている Leipzig Glossing Rules(LGR)[13]という、インターリニア・グロス(各単語の意味、各形態素の意味を本文と訳の間に書くもの)を書くようにとの指示を筆者の母語である関西方言の口語で入力したものである。
確かに、それぞれの単語と形態素の説明は出力でできているが、LGR にような本文―グロス―訳の層をなすインターリニア・グロスを作っていない。さらに、「わたし」を「主格(nominative case)」とする誤りも犯している。というのも、日本語共通語では、「わたしが」のように主格の格助詞「が」を用いて主格が表わされ、「わたし」だけでは格情報は分からないからである。また、最後の列の「1.TOP 3.GEN 5.INST 7.COP」というのは、それらの番号が振られた単語と依存関係にある単語の意味を書いているのであろうが、これは余分な情報である。
筆者が求めていた結果は次の図2である。

このように、例を出さず、いきなり指示だけをプロンプトに入力すると、大規模言語モデル(LLM)は、事前に学習した内容からのみ出力を出す。このように、ヒントなどを与えず、指示のみ入力することを、ゼロショットプロンプティングという。それに対して、ヒントや例を与えて指示を行うフューショットプロンプティングでは、出力される結果の精度は高くなる。ゼロショットでは、ヒントや例を与えなかった。そのため、ChatGPT は学習したデータから答えを出さなければならなかった。しかし、フューショットでは、入力時にヒントや例を与えることで、GPT-4が学習した以外の情報も加わって、ChatGPT がより柔軟により正確に結果を出力することができる。図3は、Prompt Engineering Guide に載っているフューショットプロンプティングの例[14]を参考にしたプロンプトとその結果である。
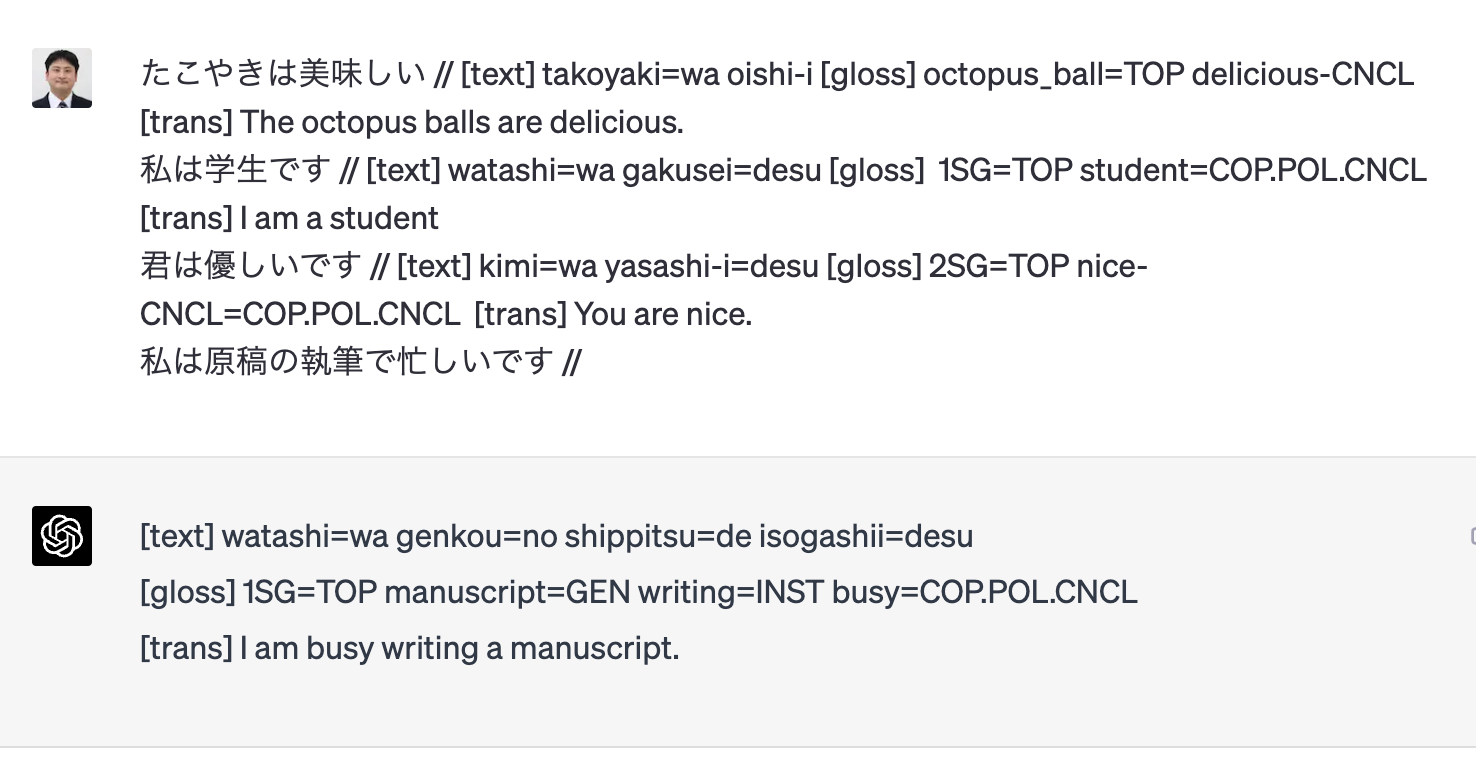
これは、「たこやきは美味しい」「私は学生です」「君は優しいです」という3つの文の解析例を先に示してから、GPT-4に解析させたものである。例えば、最初の「たこやきは美味しい」の例では、例文を書いた後に「//」を入れ、その後に、接辞境界に「-」を、接語境界に「=」を挿入してローマ字化したテキストである [text](takoyaki=wa oishi-i)を書いた。接語とは、それ自体はアクセントを持たないが、接辞よりは「単語」のように文法的に振る舞う語のことであり、日本語では格助詞やコピュラなどが接語だと言われる。その後、[gloss] と書き、当該テキストの形態素解析の結果を LGR に則り、octopus_ball=TOP delicious-CNCL と書いた。TOP は主題の略号で、日本語の副助詞の「は」は主題/トピックを表すとされているためであり、CNCL は終止形(conclusive)の略号で、これ自体は LGR にはないものの、LGR スタイルで終止形を表すときにこの略号はしばしば使われる。[trans] のあとは英語で「たこやきは美味しい」のテキストの翻訳をした。
この要領で、「たこやきは美味しい」のほかにも「 私は学生です」に対して 「 [text] watashi=wa gakusei=desu [gloss] 1SG=TOP student=COP.POL.CNCL [trans] I am a student」[15]、「 君は優しいです」に対して 「 [text] kimi=wa yasashi-i=desu [gloss] 2SG=TOP nice-CNCL=COP.POL.CNCL [trans] You are nice.」という解析例を与えた。これらの解析例を提示した上で「私は原稿の執筆で忙しいです //」と、解析させたい文を書き、そのあと「//」を付し、そのあとは空欄のままとした。こうすることで、GPT-4は、解析例のように「//」のあとに解析結果を書かなければいけないことを推測し、「[text] watashi=wa genkou=no shippitsu=de isogashii=des-u [gloss] 1SG=TOP manuscript=GEN writing=INST busy=COP.POL-CNCL [trans] I am busy writing a manuscript.」[16]というテキストを出力した。この出力結果はほぼ正解であるものの、isogashi-i の -i の部分を解析し損ねている。これは、解析例の oishi-i (delicious-CNCL) から推測するべきであったが、うまく行かなかった。それでも、三つ例を示すだけで、例に入っていない単語や構文まで正解に近い解析結果を出せたのは驚異的である。
このようなフューショットプロンプティングのテクニックの解説が最近増えつつある。筆者が参考にしたものは、LinkedIn の動画講座「Introduction to Prompt Engineering for Generative AI」[17]、および、DAIR.AI のテキスト講座「Prompt Engineering Guide」[18]である。後者の解説文については、日本語訳もなされている[19]。このような教材が増え、生成系 AI により良い出力結果を出させる技術であるプロンプトエンジニアリングの知識が広まることが期待される。