人文情報学月報第139号
目次
- 《巻頭言》「古文書のデータ化と向きあう」
:人間文化研究機構国立歴史民俗博物館 - 《連載》「Digital Japanese Studies
寸見」第95回
「国会図書館が遠隔研修として「デジタル資料の長期保存に関する基礎知識」を追加」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第56回
「Surface Syntactic Universal Dependencies (SUD) による依存・係り受け統語構造記述」
:人間文化研究機構国立国語研究所研究系 - 《連載》「仏教学のためのデジタルツール」第4回
「The Buddhist Digital Resource Center (BDRC)」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「古文書のデータ化と向きあう」
日本の歴史研究をおこなう上で、古文書を扱うことは最も重要な取り組みの一つである。特に江戸時代以降、全国各地で膨大な記録が生成され、文書主義とも形容される社会が展開した。その結果、現在でも各家々に江戸時代以来の古文書が大量に保管されており、日本の近世・近代史研究はもちろん、日本社会の成り立ちを理解する基礎的な資料として重視されている。
日本史、特に近世以降の歴史研究は、各地に点在する古文書の所在状況を調べ、博物館や公文書館、図書館などの収蔵施設、または個人宅を訪ねて古文書原本の調査を依頼することから始まる。先行研究や自治体史などにある記載から所蔵地の目星を付け、現地に赴いて1点1点閲覧・写真撮影を行っていく。研究費など持たなかった学生時代の筆者は、調査費用捻出のためにアルバイトを増やし、生活費を削ってなるべく安い宿泊地を探していた。やっとの思い出たどり着いたものの、想定通りの内容が記されているとは限らない。実際に現地で現物を確認するまでは何が残されているのか分からない、期待と不安を抱えて相対することが、古文書調査の醍醐味でもあった。
歴史資料のデジタル化に向けた近年の取り組みは、このような古文書調査のあり方に変容を促しつつある。各地の収蔵施設が進める収蔵資料のデジタル公開の動きは、自宅にいながらにして大量の古文書群を画像で閲覧することを可能にする。原本調査の場合、文化財でもある古文書に対し、その取り扱いは慎重を要し、状態によっては閲覧の制限が加えられることもある。しかし、デジタルアーカイブとして公開された古文書では、対象物の状態に配慮することなく、心ゆくまで熟覧することが許容される。加えて、「みんなで翻刻」(https://honkoku.org/)に代表される古文書読解に関わる新たなコミュニティの出現は、多様な参加者を取り込んだ古文書読解の形態をもたらし、遠隔地間での古文書読解および情報の精査を飛躍的に進展させる[1]。古文書がデジタル化され、広く社会で共有されることで、調査・研究や市民学習などの諸活動は、新たな段階を迎えつつある。
デジタル技術の進展にともない、古文書の調査・研究に向けた情報基盤は続々と整備されている。特に、コロナ禍の影響により現地調査が大きく制限された近年、デジタルデータとしての資料公開は研究者にとっても救世主のような存在であった。条件さえ整えば、現地調査を行うことなく古文書の調査から分析、研究発表に至る活動を行うことも不可能ではなくなってきている。
こうした状況を享受しつつ、ここで改めて古文書の“データ化”について考えてみたい。換言するなら、我々は古文書のいかなる要素を歴史情報として重視し、抽出・保存・継承を試みているのか、という問題である。第一義的には紙面に記された文字情報が重要であることはいうまでもない。また、筆跡に加え、文書の法量や厚さ、発給形態などの文書様式は、久米邦武や黒板勝美以来展開する日本古文書学において長く注目されてきたところである。アーカイブズ学的な観点からすると、出所・伝来経過など文書群としての構造的情報にも関心が及んでいる。これらの諸情報が古文書からデータとして抽出され、デジタル化された歴史情報として可視化されている。
さらに近年では、古文書の物質的側面に注目した分析が進展している。すなわち、古文書に使用される料紙を多角的に探る取り組みであり、料紙の繊維構造や抄紙過程で加えられた添加物を非破壊的な手法で分析するものである。こうした研究は、1990年代頃より古文書学のなかで進められたアプローチであるが[2]、ここでもデジタル技術が積極的に導入され、古文書を構成する物質的情報が精緻な分析によって可視化されようとしている[3]。
このように、デジタル技術を活用した古文書からの情報抽出は、単に文字情報に限定されず、個々の形態的情報や群としての構造的情報、さらには料紙内部におよぶ物質的情報への注目を促す。その意味で、デジタル技術による古文書のデータ化とは、長年にわたり注目されてきた古文書という媒体に内包される歴史情報を複眼的に捉え、データとして可視化する契機でもあったともいえる。では、多角的なアプローチにより抽出された膨大な情報と向きあうなかで、我々は如何なる歴史像を構築することができるのだろうか。料紙情報に象徴されるように、現在提示される諸データは、文字を読むことに留まらない視点で古文書と向きあうことを我々に要請する。可視化された多様な情報のなか、古文書の新たな研究の進展が模索されようとしている。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第95回
「国会図書館が遠隔研修として「デジタル資料の長期保存に関する基礎知識」を追加」
国立国会図書館は、2023年2月14日に遠隔研修の一環として「デジタル資料の長期保存に関する基礎知識」(以下、本研修)を公開した[1][2]。この遠隔研修は、Youtube の国立国会図書館公式チャンネルをつうじて提供されるコンテンツのひとつで[3][4]、もっとも古いコンテンツとしては2014年のものがあり、短いものであれば20分程度、長ければ大学講義1、2本分程度の内容が継続的に公開されている。
研修はレファレンス業務にかかわるもの、その他サービスにかかわるもの、資料保存にかかわるものに大別されており、今回のものはそのうちの最後に属する。海外日本研究関係者向けのコンテンツには、英語字幕の備わるものもある。レファレンスにかかわるものには、国立国会図書館の提供するツールやレファレンス協同データベースの紹介があるほか、さまざまな主題(テーマ・分野)にかんするレファレンスを行う際の基礎知識を与えるものもあり、レファレンス業務にかならずしも特化したわけではない内容については、一般の学習者にとっても有用であろう。とくに、官公庁系の情報の入手法など、なかなか一般的な知識を得がたい内容は、いち市民としても利用価値が高い。
本研修が含まれる資料保存にかかわるものとしては、紙資料の資料保存(補修、冊子体を保護するための帙の作り方など)、デジタル化の考え方、権利処理などが提供されており、紙資料中心だった図書館のデジタル対応のための基本的な知識が提供されている。今回の長期保存は、その点において、デジタル対応をしたその次を学べるもので、現時点でのいわゆるベスト・プラクティスを提供するものである。
本研修はさらに電子情報部電子情報企画課次世代システム開発研究室の担当する「記録媒体の特性の違いや課題を理解する」と題されるパート1と関西館電子図書館課の担当する「方針作成から保存システムまで」と題されるパート2とに分かれ、それぞれ60分と40分程度の内容である。
パート1では、デジタルデータがいかなるものであり、その保存がどうあるかという、分かっているつもりでなかなか感覚的な域を出にくいものについてのおさらいにはじまり、その記録媒体の特徴(保存様態、物理的性質)から長期保存計画をどのように立てるべきか、また、データの保護ではなく、コンテンツの保存はどのようにあるべきかまで注意を促すものとなっている。パート2では、長期保存がどのように問題になってきたか、どのように解決が図られ、また現時点でどのように問題であり続けているかについてのまとめがなされ、組織として対応を図っていくにあたっての計画策定と実施についての講義がされている。
パート2で参照されている「デジタル資料の長期保存に関する国内機関実態調査報告書」[5]を見ると、デジタル化の対応に四苦八苦で今後のことは後回しにされてしまっている現状も窺えるが、建造物の維持と同じで、厳格な方針をもって臨むべき点、なりゆきに従うべき点があり、ベスト・プラクティスを把握して、前者(データ保存環境の維持・見直し)が滞りなく行われるよう、あらかじめできるかぎりを図っておくべきではないかと思われる。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第56回
「Surface Syntactic Universal Dependencies (SUD) による依存・係り受け統語構造記述」
最近、言語類型論において影響力の大きい研究者であるマルティン・ハスペルマート氏が SNS 上で、Universal Dependencies (UD)[1]のヴァリアントである Surface Syntactic Universal Dependencies (SUD)[2]を取り上げることがあった。SUD は UD とは数多くの違いがある。両者とも、世界の全ての言語の文の構造(統語)を同じ規則で記述することを目的とした意欲的なプロジェクトである。今回は、SUD と UD の違いについて概説する。
統語構造記述には、大きく分けて二つの方法がある。一つ目は、語と語が句を構成し、さらに句同士、あるいは句と語がさらに句を構成していく句構造文法、あるいは、構成文法である。この句構造文法では、例えば、cat は名詞、the は決定詞[3]だが、the cat は、the を主辞 (head) と取れば限定詞句、cat を主辞と取れば名詞句である。ここで主辞とは、句のうち、主要となる句あるいは語のことである。句を構成する要素、すなわち構成素は三つ以上を許可する文法理論もあるものの、初期以外の生成文法など主要な文法理論では、句の構成素は二つだとしている。次に、the cat sleeps という文では、the cat という限定詞句と sleeps という動詞が、動詞を主辞とした動詞句を構成していると考える。このように句の上にさらに句が何重にも重なっていくのが句構造文法であり、この文法記述を樹形図で書くと、クリスマスツリーのように底辺がテキストとなる三角形を描くことができる。このような樹形図を統語樹という。
この句構造文法に対して、句という語以上の構造を考えず、文のなかの単語どうしのつながりのみを記述していく方法があり、このつながりを依存、あるいは係り受けと言い、この記述方式をとる文法を依存文法という。依存文法は古くからある考え方で、とくにルシアン・テニエール (1893–1954) [4]のものが有名である。たとえば、the cat は、the と cat の間で依存関係 (deprel) があり、cat が主辞だと考えると、(a) the が cat に依存しており、(b) the が主辞だと考えると、cat が the に依存している。the cat sleeps では、(a) では cat が sleeps に依存しており、(b) だと the が sleeps に依存していると考えられる。UD は、このうちの (a) のパターンの依存文法を採用している。すなわち、theのような機能語と cat のような内容語なら、機能語が主辞である内容語に依存していると考える。また、文の依存関係の頂点となる root は、動詞述語文の場合は、常に動詞である。これに対して、SUD では (b) のパターンをとる。すなわち、機能語が主辞となって、内容語が機能語に依存する。root は動詞のままである。機能語と内容語のあいだに依存関係がある場合、機能語が主辞となるのは、機能語が主辞となって、内容語とともに句を形成するとする近年の生成文法や認知文法の考え方と共通する部分があるため、主要な文法理論を学んだ者からは、UD よりも SUD の方が入りやすいだろう。
このように機能語を主辞とする方針が SUD を UD から区別する主要な要素であるが、そのほかにも様々な違いが両者の間に存在する。すぐに目につく違いとしては、SUD は、UD よりも依存関係タグが少ないことである。UD では、語と語の間の依存関係に、様々な関係を想定する。例えば、cats sleep であれば、cats が sleep に依存し、その依存の関係は、体言主語[5]であり、UD のルールでは nsubj とタグ付けされる。また in the bed では、the と bed では、bed を主辞とした the から bed への det(決定語)を依存関係とした関係が、in と bed では、bed を主辞とした in と bed への case(格表示[6])を依存関係とした関係がある。in と the には直接の依存関係はない。
これに対して、SUD では、in the bed ならば、まず the と bed ならば、the を主辞とする bed が the に依存する det(決定語)の依存関係があり、in と the ならば、in を主辞とし、the が in に依存する comp:obj(補語:目的語)の依存関係がある。そして、the と bed の間には、UD とは異なり、依存関係はない。また、格を表すのが、UD では case、SUD では comp:obj という依存関係の違いもある。このように、内容語と機能語があれば、UD のように内容語を主辞とする文法と、SUD のように機能語を主辞とする文法の記述方法に大きな差がでる。
依存関係タグに関しては、cats sleepでは、UD・SUD とも、cats が主辞 sleep に依存するのは一緒であるが、依存関係は、UD は nsubj(体言主語)というタグであるのに対し、SUD では単に subj(主語)というタグを用いている。UD では、主語を表す依存関係に nsubj と csubj がある。nsubj は、単に名詞や代名詞など名詞類が主語である場合である。これに対して、csubj(節主語)は、節が主語である場合である。節が主語である場合とは、例えば、[what he said] made me happy のように節である [what he said] が主語となる場合である。SUD では、このような節が主語となる場合でも名詞類が主語となる場合でも構わず subj に統一している。以下の表1は、UD と SUD のタグの違いである。
| UD | SUD |
|---|---|
| nsubj(体言主語)、 csubj(節主語) | subj(主語) |
| aux(動詞補助成分) | comp:aux(補語:動詞補助成分) |
| cop(繋辞) | comp:pred(補語:述語) |
| xcomp (節補語)、 case(格表示)、mark(標識)、obj(目的語)、ccomp(節目的語)の一部 | comp:obj(補語:目的語) |
| ccomp(節目的語)、obl(斜格補語)の一部、 iobj(間接目的語) | comp:obl(補語:斜格) |
| nmod(体言による連体修飾語) | udep(汎用依存) |
| obl(斜格補語)の一部、 acl(連体修飾節)、advcl(連用修飾節)、amod(用言による連体修飾語)、nummod(数量による修飾語)の一部 | mod(修飾語) |
| det(決定語)、nummod(数量による修飾語)の一部 | det (決定語) |
なお、表1にない依存関係については、SUD と UD は両者とも同じである。また、品詞を17に限定した UPOS(汎用品詞)もどちらも同じである。図1の樹形図は、上が SUD、下が UD のもので、コピュラ文(A = B、「A は B である」を意味する文)の記法である。UD は、コピュラ文では、補部の一部である office が root になっているのに対し、SUD では、コピュラである am が root になっている。
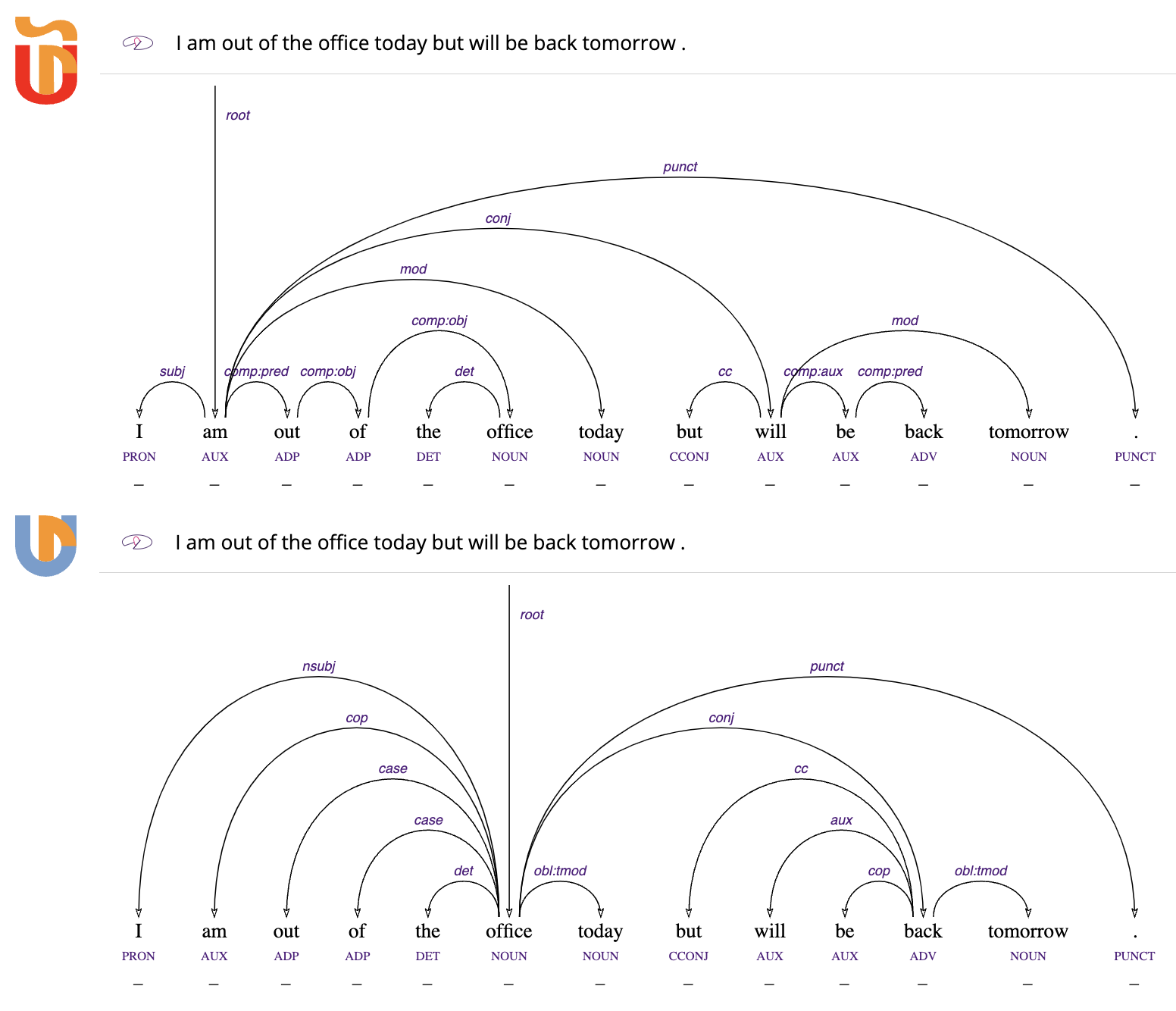
SUD の方が、生成文法的な句構造文法の主辞の認定に近いため、言語学を学んだ者は SUD の方が入りやすいかもしれない。しかしながら、UD はコピュラ文でコピュラではなく補語を root とする。これは、コピュラ文でコピュラが使われない言語と、コピュラに人称標示があるためコピュラ文で主語なしのコピュラ文が可能な言語が存在するためである。例えば、ゼロコピュラとなる現代ヘブライ語の現在時制などでのゼロコピュラ文ではコピュラがないため、補語か主語を root にせざるを得ない。他方、イタリア語などコピュラに人称変化があり主語がなくてもコピュラ文が成立する言語もある。これらの言語のことを考えると、コピュラ文で必ず存在するのは補語であり、補語を root にする方が全ての言語で同じ記述ができるためである。このように、UD の係り受け構造記述ルールには、どの言語も同じ方法で記述するという思想がある。
このように SUD と UD は、どちらも長所と短所および大きな違いがあるが、SUD のサイトによれば、UD は SUD に自動変換可能である。実際、234の UD コーパスが SUD に変換されて GitHub で公開されている[8]。よって、SUD を依存構造記述で採用する場合でも、まずコーパスを UD で作ってから、SUD に自動変換した方が効率が良いであろう。
《連載》「仏教学のためのデジタルツール」第4回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「The Buddhist Digital Resource Center (BDRC)」
The Buddhist Digital Resource Center (BDRC, https://www.bdrc.io) はボストンを拠点とし、現代の不安定な社会的、政治的、環境的要因によって消滅の危機にある仏教文献を保存し、普及させることを目的とする非営利団体である。BDRC は1999年にジーン・スミス(Gene Smith)によって設立された Tibetan Buddhist Resource Center (TBRC) を前身とする。当初は主にチベット語文献を管理していたが、プログラムの対象をアジア各地に伝わる写本や印刷物など仏教に関わるすべての文献に拡大し、2016年に BDRC へと名称を変更し現在に至る[1]。
BDRC の最大の特徴はチベット語文献をはじめ、サンスクリット語、パーリ語、漢語、ビルマ語、クメール語、モンゴル語、ロシア語などのあらゆる仏教文献を網羅的に収集し、デジタル画像として保存したものを一般に公開している点にある。BDRC によって仏教文献の共同利用プラットフォームとして開発された The Buddhist Digital Archives (BUDA) は仏教文献に関するデータベースとしては世界最大規模を誇る。
BDRC の Web サイトの表示言語はチベット語、英語、中国語(簡体字)に対応しており、現在はクメール語も整備中である。
BDRC のアクセスポリシーには次の2点が定められている。(1)生きた伝統を維持するために、文化的作品へのアクセスを最大化する。(2)著作者と出版社の法的・文化的権利を保護する。以上のことから、著作者や出版社の著作権などが侵害される恐れのある場合は文献へのアクセスが制限されることがあるが、アーカイブの大部分はパブリックドメインであり、自由にアクセスすることができる。さらに、BDRC の Web サイトでユーザー登録をしてアカウントを作成すれば、オープンアクセスの文献全体を PDF 形式で自由にダウンロードすることができる。したがって、研究に必要な作品はオフラインでも常に手元に置いておけるので、少なくともチベット語文献については図書館や研究室に出向いてコピーを取ってくるという作業が不要となった。
BUDA の検索システムを通じて目的の文献のデジタル画像を閲覧あるいはダウンロードしたい場合には、文献名や著作者名から検索すると見つけやすい。文献名や著作者名に関しては多数の異名が登録されており、また検索条件は部分一致方式が採用されているため、目的の文献は探しやすく、註釈書などの関連文献も一度で豊富に検索できる。検索システムには絞り込み機能があり、“Works”(作品)、“Versions”(版)、“Etexts”(電子テキスト内の全文一致検索)、“Persons”(人物)、“Places”(場所)などといった項目を設定することで、検索結果をカテゴリーごとに抽出することができる。
目的の文献が探せたら、画像ビューアで写本や印刷物などのデジタル画像が確認できる。画像ビューアは文献をページ単位で表示することもできるし、連続スクロールで表示することもできる。また、閲覧しやすくするためにコントラストや彩度、明るさなどの調節、色調を反転させるといったことなどもできる。
文献の書誌情報欄には他の多数の機関・プロジェクト(SAT, CBETA, 84000, rKTs, Cambridge Digital Library, etc.)のリンクが貼られているため、当該文献の電子テキスト、翻訳、目録情報、別版のデジタル画像、関連文献などといった情報も取得しやすい。さらに、書誌情報だけでなく、著作者情報として称号や異名、師弟関係、父母、生没年、出生地、学派、関係僧院などもデータベース化されており、またその典拠となる文献も併せて参照できるため、学術研究を行ううえで大変有用である。
BDRC は上記のようなデータベースを日々更新し拡張しつつ、現在は東南アジアにおける2つのプロジェクトを遂行している。1つはタイを拠点とする“The Fragile Palm Leaves Digitization Initiative”である。このプロジェクトの主な活動はピーター・スキリング氏によって収集されたビルマのヤシの葉写本、およびその他さまざまな言語・形式で書かれた写本のデジタル化である。もう1つの主要なプロジェクトは“The Khmer Manuscript Heritage Project”といい、L'Ecole française d'Extrême-Orient と Digital Divide Data の協力のもとクメール語写本のデジタル化が行われている。
以上のように、膨大な量の情報を備えた BDRC のアーカイブは仏教文献の宝庫といえる。使用者によってさまざまな使い方が考えられる。言語を問わず何らかの仏教文献の情報を得たい場合には、まずは BDRC の Web サイトに立ち寄ることをおすすめしたい。
人文情報学イベント関連カレンダー
【2023年3月】
-
2023-3-1 (Wed)
19th CODH Seminar Collective Intelligence and Creative AI: A framework for augmenting creative human expression於・オンラインhttp://codh.rois.ac.jp/seminar/creative-ai-20230301/ -
2023-3-4 (Sat)
ことば・認知・インタラクション11於・国立情報学研究所https://www.ninjal.ac.jp/events_jp/20230304b/
Digital Humanities Events カレンダー共同編集人
◆編集後記
今月は《連載》「デジタル・ヒストリーの小部屋」が休載です。本メールマガジンにて掲載している貴重な連載群は、いずれも気鋭の若手研究者の方々に頑張っていただいておりますが、あくまでも無理のない範囲でのご執筆をお願いしておりますので、ご理解をいただけますと幸いです。
2月はケンブリッジ大学図書館におけるデジタル図書館や詳細なデジタル書誌作成に関する専門家を日本に招聘しての講演会が2回開催されました。世界でもトップクラスの大学で、図書館がデジタル技術を通じてどのように人文学を支援しているか、ということが丁寧かつ詳細に報告され、今後の人文学と図書館の関係について多くの示唆が得られたように思います。これについては、次号で何らかの形でご報告させていただきたいと思っておりますのでよろしくお願いいたします。