人文情報学月報第138号【前編】
目次
【前編】
- 《巻頭言》「戦前の法令を調べる」
:名古屋大学大学院法学研究科 - 《連載》「Digital Japanese Studies
寸見」第94回
「国立国会図書館デジタルコレクションがリニューアルし、全文検索の提供が充実するとともに NDL ラボにおける Ngram ビューワとデータセットの提供が拡充される」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第55回
「「キリシタン・バンク」と「みんなで翻刻」:キリシタン版翻刻のクラウドプラットフォーム」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第13回
「(技術レビュー)Jonathan Blaney et al., Doing Digital History: A Beginner's Guide to Working With Text As Data (IHR Research Guides), Manchester University Press, 2021」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第3回
「花園大学国際禅学研究所 電子達磨#3」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「戦前の法令を調べる」
私は、法学に属する研究者で、人文学は全くの専門外の者です。ただし、法学の中でも、情報科学と接点を有する法情報学[1]を専門としているので、人文情報学とはややつながりがあると言えそうです。最近は、法令データベースの構築に取り組んでおり、特に戦前の法律・勅令のデータ整備を進めています。
法令が、法学において最も重要な情報であることは言うまでもありませんが、他の分野においてもその重要性は低くないのではないでしょうか。私が関わっている『人事興信録』研究[2]にも次のような例があります。『人事興信録』は、近代日本社会の最上層の人々を採録した人物情報誌で、レファレンス資料として様々な分野で幅広く活用されている資料です。そこには「東京府平民」のように、その人物の族称が記載されていますが、第8版から「平民」の表記がなくなり「在籍」となります。これは、戸籍法が大正3年に改正されて、華族と士族以外は族称を付さないこととなった影響だと考えられます。このように、近代の資料の読解においても、法令の知識が必要になる場合があります。
しかし、過去の法令を調べることは、簡単ではありません。法令は、政府が提供する「e-Gov 法令検索」(https://elaws.e-gov.go.jp/)を使って検索できます。このデータベース以前も政府は「法令データ提供システム」を提供していて、法令を検索することができました。両者はいずれも現行法令のデータベースと位置づけられていて、過去の法令を閲覧することはできません。
過去の法令を探す手がかりとなるデータベースとして、国立国会図書館(以下 NDL)の「日本法令索引」(https://hourei.ndl.go.jp/)があります。法令ごとにページがあり、公布日や改正、廃止といった法令の履歴情報を把握することができます。戦前の法令については、NDL デジタルコレクションや国立公文書館デジタルアーカイブへのリンクが掲載されているので、画像で本文を確認できます。さらに、法令の帝国議会での審議経過を表示することもでき、帝国議会会議録検索システム(https://teikokugikai-i.ndl.go.jp/)を通じて内容を参照できます。法令単位で様々な情報を見ることができる、ワンストップなデータベースと言えます。
しかし、このデータベースは法令本文のデータを持っているわけではないため、キーワード検索としては、法令名による検索となります。そのため、法令名が部分的にでもわかっているとか、調査事項が法令名に入っている場合でないと見つけることができません。また、法律と勅令は網羅されていますが、省令以下の下位法令は、収録されていないものが多くあるので注意が必要です。
キーワード検索という点では、NDL デジタルコレクションを利用する方法が考えられます。法令は、官報で公布されることとなっているので、官報が底本に当たります。官報は、コレクションの一つとしてまとめられていて、官報に特化した検索ができます。2022年12月21日のリニューアルにより全文検索機能が追加されたことで、検索による発見の可能性は飛躍的に高まりました。ただし、官報には法令以外の情報も掲載されているので、不必要な情報がマッチすることも少なくありません。
ちなみに、法令のみを種類ごとにまとめ直した『法令全書』という便利な書籍もありますが、残念ながら、デジタルコレクションには明治45年までのものしか収録されていません。また、法令集として「六法全書」という言葉が世間ではよく知られていると思いますが、この種の書籍は、主要な法令が掲載されているものの、網羅的に法令を掲載してはいません。
ここまでで、多少の課題はあるものの、日本法令索引とデジタルコレクションを駆使すれば、法令を検索したり閲覧したりできるように思われたかもしれません。しかし、法令が改正された場合、実は、改正後の条文を閲覧できるわけではありません。法令の改正には、一部改正と全部改正の2種類があります。全部改正の場合は、改正後の全文が掲載されますが、一部改正の場合には、次のような条文の修正を指示する「改め文」と呼ばれる法令文が掲載されるだけです。
第五十五條中「選擧ヲ行フトキハ」ノ下ニ「本法中別段ノ規定アル場合ヲ除ク外」ヲ加ヘ「匿名投票」ヲ「無記名投票」ニ「同年月ナルトキ」ヲ「年齡同シキトキ」ニ改メ「其ノ他ハ第十八條第二十七條及第二十八條ノ規定ヲ準用ス」ヲ削リ第二項ヲ左ノ如ク改ム
改め文の指示を元の条文に適用しなければ、改正後の条文を知ることができません。改正が複数回されている場合は、この適用作業を順次繰り返す必要があります。改正後の条文が公的に示されることは基本的になく、改め文の適用作業は、民間の出版社により行われてきました。前述の「六法全書」は、まさにこれにあたります。
すべての法令に対して改正バージョンごとのテキストを作成するためには、膨大な回数の適用作業を行う必要があります。膨大な適用作業を正確に行う方法として、コンピュータを利用することが考えられます。実際に改め文の適用を自動化した研究があり、高い精度で可能なことがわかっています[3]。しかし、これを実行するためには、正確なテキストが必要となります。それだけではなく、改め文の例からわかる通り、テキスト中の「第五十五條」や「第二項」といった箇所をコンピュータが正確に判断できなければなりません。そのためには、法令が単なるテキストデータではなく、マークアップされた XML 文書であることが必要です。また、上記の研究は、戦後の法律を対象とした実験であるため、戦前の法令の文書形式への対応を検討する必要があります。加えて、テキストデータの誤りなどにより改め文を機械的に適用できない場面も想定されるため、これに対処できるような実用的なプロセスを検討する必要もあります。
名古屋大学法学研究科の「日本研究のための歴史情報プロジェクト」では、法令データベースの構築を目指し、その最初の作業として、戦前の法律と勅令のテキストデータの作成と XML 文書化を進めています[4]。改め文の自動適用を行い、法律と勅令の全バージョンのデータを作成することが、当面の目標です。
法令を利用することは、法学以外の分野からは、ハードルが高いことであったように思われます。デジタル技術の利用は、分野の壁を乗り越える有力な方法だと思います。まだ少し先のことになると思いますが、法令データベースを公開できた際には、人文学の分野からも利用されることを期待しています。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第94回
「国立国会図書館デジタルコレクションがリニューアルし、全文検索の提供が充実するとともに NDL ラボにおける Ngram ビューワとデータセットの提供が拡充される」
国立国会図書館は、2022年12月21日、国立国会図書館デジタルコレクション(以下 NDL デジタルコレクション)[1]をリニューアルするとともに[2]、2023年1月10日には、NDL ラボにおいて、すでに提供されていた NDL Ngram Viewer[3]とそのソースコードおよびデータセットの公開が対応して拡充された[4]。後者については、試験公開時に取り上げていなかったので、あらためて公開からの経緯についても触れたい。
NDL デジタルコレクションについては、かつて公開時に本連載で触れたことがある[5]。その後、図書館や個人向けデジタル化資料送信サービスの開始があり[6]、NDL ラボにおいても、あらたな展開にむけた試みが着々となされてきたことは、折りに触れてお伝えしてきたところである[7][8]。今般のリニューアルは、これらの成果を盛り込み、かつ、こまかな点の見直しが図られたもので、まずは歓迎したい。
そっくりそのままではないにせよ、次世代デジタルライブラリーの成果の多くが取り込まれている。その第一は、やはり、[8]でも述べた OCR データの改善と拡充である。その後、OCR エンジンの入れ替えと対象点数の拡充により、読取り品質の向上と、247万点までの拡充(これまでは5万点)がもたらされた。この間の OCR 技術の精度向上などもあって、利便性の向上は見かけ上の数値以上に大きい。第二には、画像検索機能の追加である。公開画像や手元の画像からその一部や全部と類似する画像を検索することができるようになった。
このほか、認証機能の改善がされた。いままでは国立国会図書館オンライン[9]、国立国会図書館サーチ[10]、NDL デジタルコレクションのそれぞれで認証をする必要があったが、シングルサインオン機能の導入により、いずれかにログインすることで足りるようになったという。NDL デジタルコレクション内でも、これまでは送信サービスを利用するためのログインが後付けというためもあってスムーズにはできなかったが、シームレスな利用がしやすくなった点はたいへんありがたいところである。また、個人向け送信サービスでは印刷が禁止されていたが、2023年1月18日から可能になったのもうれしい[11]。画像ダウンロードとは異なり、利用者名等の記された印刷用 PDF ファイルが生成されるようになっている。
そのいっぽう、機能の増大によって、これまでの一画面にすべてが収まっていたような利便性は損なわれてしまい、内部フレームの増加による操作の難化や、画像ダウンロードの場所などが離れてしまったなどのこともあり、アクセシビリティについては研究の余地があるのかと思われた。画像の表示サイズをフレームに合わせる機能がなくなってしまったのも、個人的には残念なところである。
NDL Ngram Viewer とそのソースコード・データセットの公開は、試行版として NDL ラボで2022年5月31日に公開されはじめたもので[12]、NDL デジタルコレクションの OCR データ拡充にあわせて2023年1月10日からデータの拡充がなされた。詳細については開発に携わっている青池亨氏の報告がある[13]。Ngram Viewer は、たんに OCR データの検索が可能なだけではなく、正規表現での検索や複数検索をサポートしているという点で使い勝手のよいものとなっている。公開当初は、著作権保護期間の満了した図書資料28万点に限定されていたが、雑誌資料や著作権保護期間内の資料も加わったことにより、230万点から検索ができるようになっているとのことである。これは、NDL デジタルコレクションで検索可能な資料のうち、博士論文や官報等、Ngram Viewer の対象とされていない資料を除した数と同程度ではないかと思われる[14]。
大規模 Ngram データの有用性はあらためて説くまでもないが、その実用例としては[13]の報告に加え、国立国会図書館の徳原直子・青池亨両氏による発表資料が参考となろう[15]。
なお、[8]でも触れたが、OCR データ拡充に用いられたものとはべつに開発された OCR アプリケーションがあり、そちらも2022年4月25日に公開されている[16]。これを応用したものとして、古典籍 OCR が開発されており[17][18]、さっそく、次世代デジタルライブラリーで検索対象として実証実験が行われている。
これらは、[19]で触れたような、これからのビジョンを実現する強力な一歩であるのは疑いがない。目新しさはないかもしれないが、着実に歩が進められ、それによって確実にすぐれたサービスへと繫がっていることに畏敬の念を新たにするものである。これから、これらのサービスやデータを活用した内外のあらたな成果が陸続と発表されることがじつに楽しみである。
なお、発表資料が以下からダウンロードできる:
https://lab.ndl.go.jp/pdf/about/jinmoncon2022.pdf。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第55回
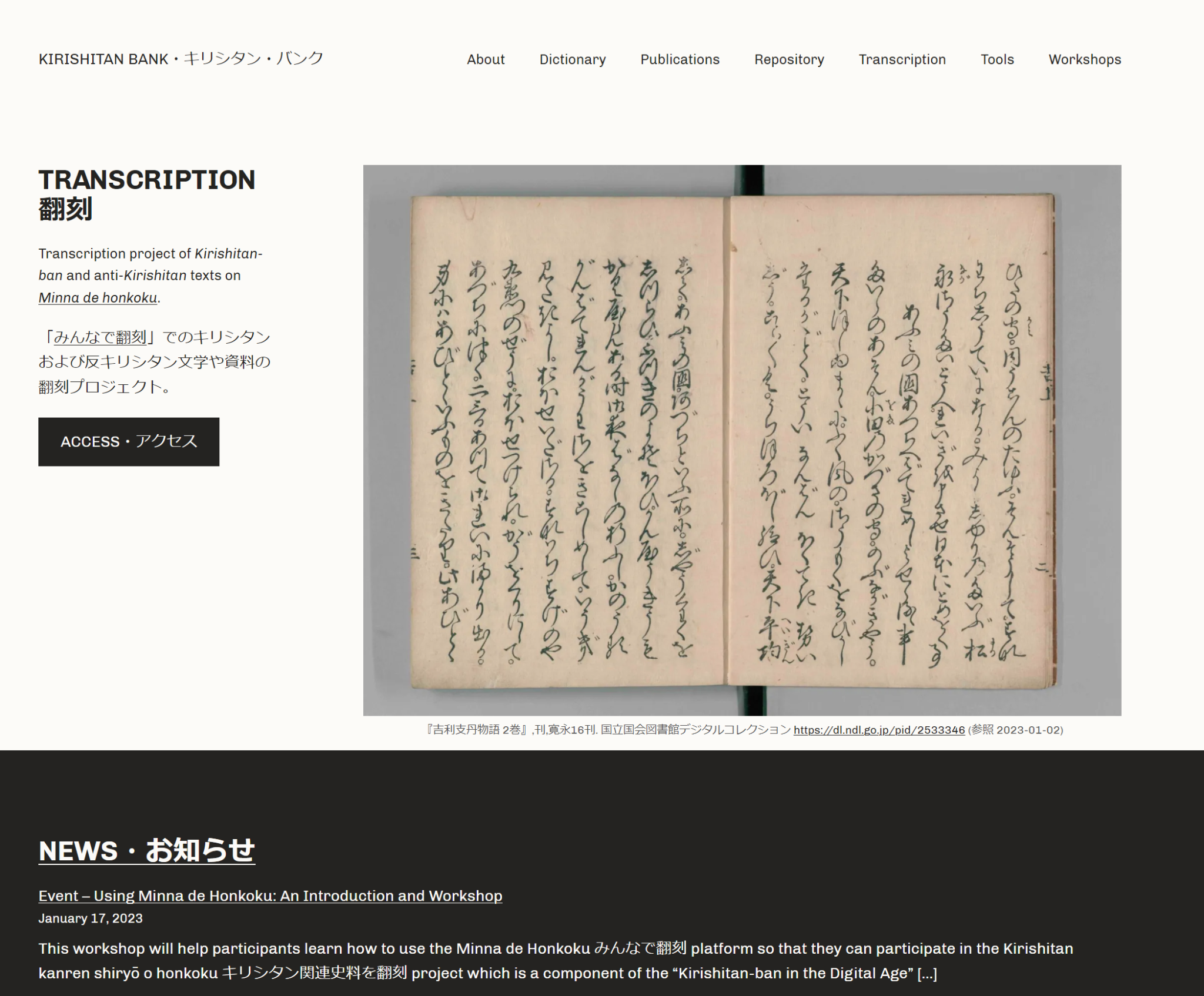
「「キリシタン・バンク」と「みんなで翻刻」:キリシタン版翻刻のクラウドプラットフォーム」
2023年1月13日、早稲田大学のジェームズ・ハリー・モリス(James Harry Morris)氏が「キリシタン・バンク」[1]をスタートさせた。これは日本のキリシタン史料の総合ポータルサイトである(図1)。モリス氏によれば、このウェブサイトを、キリシタン史料の文献画像、辞書、OCR モデル、イベント・ワークショップ情報など、豊富なコンテンツを持つ大規模総合ポータルにしていく予定であるという。これは、DNP 文化振興財団[2]による助成を受けた「デジタル時代におけるキリシタン版:デジタル手法による『キリシタン版』探索の可能性と限界に関する考察」という研究プロジェクトの一環である。そして、このプロジェクトの始動時点の現段階で最も大きなコンテンツは、「みんなで翻刻」[3]との共同プロジェクトである、キリシタン関連史料の翻刻クラウドソーシングプロジェクト「キリシタン関連史料を翻刻」[4]である。「みんなで翻刻」については、『人文情報学月報』内で何度も取り上げられてきたため、ここで詳しく述べる必要はないと思われるが、端的に言えば、くずし字も含めた日本の古文書や版本などの史料・文献資料の翻刻を、有志の一般ユーザが進めていくプラットフォームである。このプラットフォーム上には、現在、「翻刻!地震史料」[5]や「日本の仏典を翻刻」[6]や「茨城大学図書館所蔵資料を翻刻」[7]、「関西大学の多彩な東アジア研究資料を翻刻!」[8]など、23のプロジェクトがある。翻刻する対象の区分も仏典、地震史料など文献のジャンルによるものもあれば、特定の図書館や研究施設などの所蔵館によるものもある。ハワイ大学・琉球大学の琉球関連史料を翻刻する「琉球・沖縄の世界を翻刻する」[9]のように、所蔵館とジャンル両方によるものもある。この「キリシタン・バンク」と「みんなで翻刻」の共同プロジェクトは、いわゆる「キリシタン版」と反キリシタン文書(反耶蘇書)の翻刻を行う。
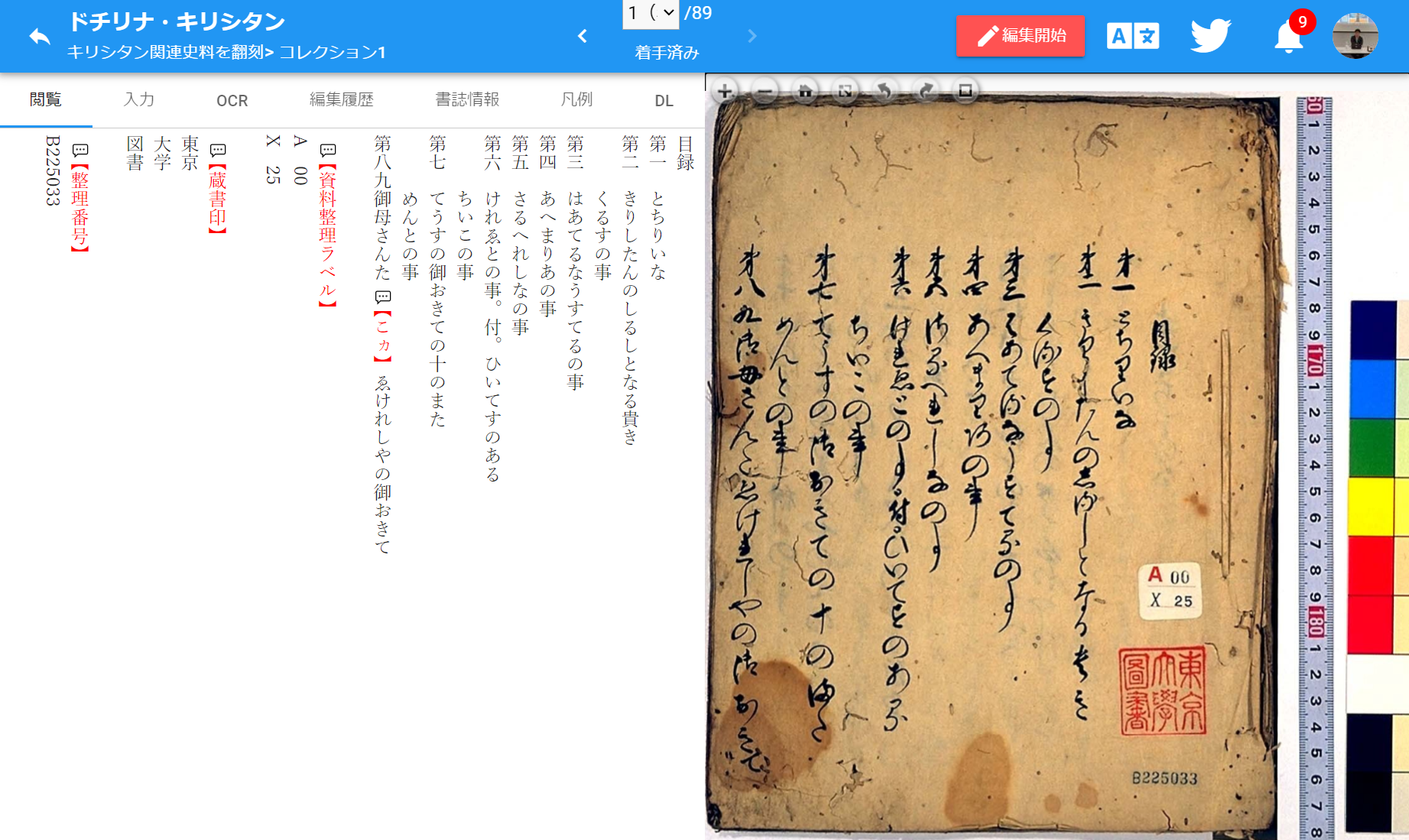
そもそも、キリシタン版とは、16世紀~17世紀に主にイエズス会が日本でキリスト教の布教を目的に出版した諸本のことである。それらの多くは天正遣欧使節 (1582–1590) が欧州から持ち帰ったグーテンベルク印刷機で印刷された。ただし、キリシタン版にはドミニコ会によるものや海外で印刷されたものも少数ある。ジャンルは、キリスト教の宗教書が多いが、日本語読本として印刷された日本の『平家物語』や日本語文法書などもある。日本語のキリシタン版には、横書きのローマ字本と縦書きの国字本があるが、「みんなで翻刻」上にある本プロジェクトのキリシタン版は、現在のところ、全て縦書きの国字本である。図2は、東京大学総合図書館所蔵のキリシタン写本の一つ、『ドチリナ・キリシタン』[10]を、「みんなで翻刻」上で入力した後の画面である。「みんなで翻刻」では、翻刻の助けとして、CODH と凸版印刷のそれぞれの OCR モデルによる文字判読の機械推測が行える他、現代ではあまり使用しない特殊な文字を、画面のボタンから入力していくことができる。また、翻刻が終わったら、SNS でそれをシェアしたり、他のユーザに添削をリクエストすることもできる、ソーシャルな機能も充実している。
2023年1月16日、「キリシタン・バンク」を立ち上げたモリス氏にインタビューを願い出たところ、了承いただき、同日にインタビューを行った。以下、モリス氏への6つの質問と氏の応答をお届けする。
- キリシタン版に関する様々なデジタルツールの正確性、有効性、限界について予備的な分析を行う。
- キリシタン版の多言語・多文字性、その内容や物質性がデジタル人文学研究者に与える問題と可能性を探る。
- 研究者や有識者でない方を支援するための簡単なツールを開発する。
モリスさん、「キリシタン・バンク」について教えていただき、ありがとうございました。