人文情報学月報第120号【後編】
目次
【前編】
- 《巻頭言》「デジタル・アーカイヴの手触り」
:慶應義塾ミュージアム・コモンズ/慶應義塾大学アート・センター - 《連載》「Digital Japanese Studies
寸見」第76回
「北米日本研究資料調整協議会が NCC Japanese Digital Image Gateway を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第37回
「ヒエログリフの機械翻訳を目指したゲーム会社・IT 企業・研究機関の国際共同プロジェクト Fabricius」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「ワークショップ「イスラーム研究用デジタルヒューマニティーズ:アラビア文字テキストのための TEI XML」(Islamicate Digital Humanities: TEI XML for Arabic-Script Texts)」
:岡山大学学術研究院社会文化科学学域 - イベントレポート「ワークショップ「Historical Networks — Réseaux Histriques — Historische Netzwerke conference 2021」」
:東京大学大学院人文社会系研究科 - イベントレポート「「2021年度アート・ドキュメンテーション学会年次大会」参加報告(前編)」
:東京大学大学院学際情報学府 - 編集後記
人文情報学イベント関連カレンダー
【2021年8月】
-
2021-08-21 (Sat)
デジタル・ヒューマニティーズ Summer Days 2021 — Transkribus於・オンラインhttps://connectivity.aa-ken.jp/activity/322/ -
2021-08-28 (Sat)
デジタル・ヒューマニティーズ Summer Days 2021 — GIS於・オンラインhttps://connectivity.aa-ken.jp/activity/322/ -
2021-08-28 (Sat)
第127回 人文科学とコンピュータ研究会発表会於・オンラインhttp://www.jinmoncom.jp/index.php?CH127
【2021年9月】
-
2021-09-04 (Sat)
デジタル・ヒューマニティーズ Summer Days 2021 — RDF於・オンラインhttps://connectivity.aa-ken.jp/activity/322/ -
2021-09-06 (Mon)~2021-09-08 (Wed)
JADH2021: "Digital Humanities and COVID-19"於・オンラインhttps://dh2021.adho.org/jadh-2021/ -
2021-09-11 (Sat)
デジタル・ヒューマニティーズ Summer Days 2021 — TEI於・オンラインhttps://connectivity.aa-ken.jp/activity/322/
【2021年10月】
-
2021-10-25 (Mon), 2021-10-27 (Wed)
Next Gen TEI, 2021於・オンラインhttps://tei-c.org/next-gen-tei-2021/ -
2021-10-30 (Sat)~2021-10-31 (Sun)
第30回地理情報システム学会研究発表大会於・オンラインhttps://www.gisa-japan.org/conferences/index.html
Digital Humanities Events カレンダー共同編集人
イベントレポート「ワークショップ「イスラーム研究用デジタルヒューマニティーズ:アラビア文字テキストのための TEI XML」(Islamicate Digital Humanities: TEI XML for Arabic-Script Texts)」
報告者は TEI[1]の存在を5年ほど前に知り、国内外のワークショップに何度か参加した。しかし、報告者が扱う資料はアラビア語やペルシア語である。右から左へ読む。左から右に入力していく XML ファイルにどうやって入力するのかと質問しても、答えてくれる人は当時いなかった。自分の研究には使えないものと思い込んでいたのだが、東京外国語大学アジア・アフリカ言語文化研究所の熊倉和歌子さんを代表者とする「デジタルヒューマニティーズ的手法によるコネクティビティ分析」(JSPS 科研費20H05830)の研究分担者に加えていただいたことにより、アラビア文字テキストのための TEI に取り組むことになった。同じく研究分担者である永崎研宣先生(人文情報学研究所)の勧めにより、月曜日と火曜日の午前中にオンライン勉強会を行っているのだが、この勉強会の効果は大きい。参加者が疑問を持ち寄り、協力して調べ、教え合うことで、すぐに基本操作を身につけることができた。そこに、デューク大学が表題のワークショップ[2]を開催するとの情報をいただき、熊倉さんと二人で参加することにした。
オンラインであるが参加者は10人までということで、参加登録には CV に加え、自分の関心についての one paragraph 英作文が必要であった。報告者は研究者情報を ORCID[3]できちんと管理していなかったことを後悔しつつ、専門とするイスラーム神秘主義の主要作品を TEI 化することで用語の変遷を明らかにしたいこと、クルアーンやハディースの日亜対訳を TEI で作成していること、最後にアラビア文字テキスト TEI の日本における先駆者になりたいとの野望を書いて送った。選考結果を待つこと半月ほどで、Zoom の URL と事前に準備しておくべきこと(以下の3点)が送られてきた。
- GitHub[4]にアカウント登録しておくこと。
- GitHub Desktop[5]をインストールしておくこと。
- Oxygen XML Editor[6]をインストールし、30日間の無料試用登録をしておくこと。
その後、参考動画サイトの URL[7]と、Oxygen が2カ月無料で試せるライセンスキーも送られてきた。事前準備を済ませ、ワークショップ当日を待つ。開催は2021年6月22日と24日、日本時間の深夜11時から1時に当たる。参加できなくても録画が見られるようにするとの連絡があったが、直接質問できる機会を逃したくない。仮眠してから臨んだ初日、一時間前に試しに Zoom に接続してみたところ、時差の計算を間違えていたことに気付く。心の準備をする間もなく参加することになった。画面上にイスラーム学界の大御所が映っており、一瞬だけ眠気が覚めたはずなのだが、報告者はよほど眠そうな顔と口ぶりで自己紹介をしたのだろう。日本が深夜であることは分かっているから無理しないでね、と優しい言葉をかけていただいた。
さて、ワークショップはアメリカ、ドイツ、エジプト、日本から7人の受講者が集まり、デューク大学歴史学部の Adam Mestyan 助教が進行し、同大学図書館 Digital Humanities Senior Programmer である Hugh Cayless 氏が補足するという形であった。二人は受講者の様子を絶えず確認し、質問しやすい雰囲気を作ってくれた。一日目は、TEI でテキストを機械可読化することの意義や、XML ファイルの基本構造についての説明から始まった。続いて、大きなプロジェクトでの共同作業を念頭に、GitHub の使い方の説明に移ったのが印象深い。必要とする研究基礎技能が、まだまだ個人研究を中心とする日本とは異なるようだ。Fetch、Fork、Clone a Repository などの機能を学び、いよいよアラビア語のテキストファイルを Oxygen で開く[8]。右から左へ向かうアラビア語テキストの場合、ピリオドが文頭に来てしまったり、タグ付けしたいテキストをうまく範囲指定できなかったりすることがある。しかし、次の方法で対処できる。
- 左下の「作者」タブを開く。
- タグ付けしたいテキストの範囲をドラッグで指定する[9]。
- 「Ctrl (Command) + E」でタグの指定をする。
付けたタグの確認をしたい場合は、ツールバーの最下段左端にある「部分タグ」でタグの表示を設定すればよい。たとえば、聖典クルアーン開扉章(al-Fātiḥa)の節(āya)に <l> で番号を付け、「属性を備えたフルタグ」で表示すると、以下のようになる。
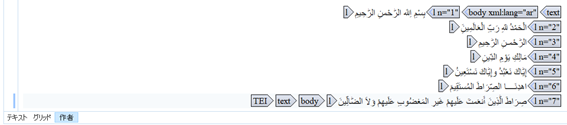
初日の講習は以上であった。宿題は、(1)<teiHeader> に書誌情報を入力すること、(2)サンプルのアラビア語テキストを <seg> で分けること、(3)日付に <date> を付けること、(4)イスラーム法学の専門用語に <term> を付けることであった。ちなみにサンプルは、「奴隷の父親と自由人の母親から生まれた子供は、奴隷か自由人か」という質問に対して出された、19世紀エジプトのイスラーム法学的回答(fatwā)である。
一日空けて二日目。<seg> などの要素タグに属性や値を付ける方法の説明から始まった。「作者」タブを開いて、テキストの質問部分と回答部分に <seg> を付ける。質問部分の <seg> タグをダブルクリックすると、「要素(Element):seg」と表示されたウィンドウがでてくる。「名前(Name)」に type、「値(Value)」に question と入力する。これで <seg> が <seg type="question"> となり、タグ付けされた部分のテキストには質問が書かれていることが機械可読化される。
続いて、やはり共同作業が念頭にあるためか、作業担当者を示すための <respStmt> や <resp>、GitHub を利用した作業の共有方法が取り上げられた。その次は、アラビア語のヒジュラ暦を数字で表示する方法であった。<date> の属性から when-custom を選んで名前とし、値に YYYY-MM-DD 式で入力する。たとえば、ヒジュラ暦1282年ラビーウ・サーニー月(Rabīʻ al-Thānī)21日は、1282-04-21とする。

さらに、値へのアラビア語の入力、校訂に必要な <sic> や <supplied>、<ref> による外部リンク、<xml:lang> による使用言語の指定など、実践的な内容が続いた。CSS ファイルと XSLT ファイル、Oxygen での単語検索方法などに触れたところで時間切れとなった。
ワークショップ終了後、デューク大学のサイトに保存された録画の URL が参加者に送られてきた。本稿執筆時点でもリンクは有効であり、復習に活用させていただいている。実は、本ワークショップの録画を YouTube の ArabicTEI チャンネル[10]にもアップロードしたとの連絡があったのだが、報告者が自分の顔と名前を隠してほしいとお願いしたところ、録画自体が削除されてしまった。ワークショップに参加できなかった人の学ぶ機会を失わせてしまったことになる。その点は申し訳なく思うため、今回学んだ内容は、録画の公開という形ではない方法で伝えていきたい。そのために本稿を執筆させていただいた。熊倉科研においてもイスラーム研究のための TEI 講習会を企画しているので、録画を見そびれた方にはお許しいただきたい。
イベントレポート「Historical Networks — Réseaux Histriques — Historische Netzwerke conference 2021」
2021年6月30日から7月2日にかけて、ルクセンブルク大学 C2DH をホストとして、Historical Networks — Réseaux Historiques — Historische Netzwerke conference 2021がオンラインで開催された。このカンファレンスは、歴史研究におけるネットワーク分析利用を幅広く議論するコミュニティである Historical Network Research(HNR)が2013年以降、毎年開催する年次総会である[1]。HNR はカンファレンスのほかにも、Journal of Historical Network Research という学会誌を2017年から発行しており[2]、ネットワーク分析という手法に関心を持つ様々な分野の歴史研究者が一堂に会する、非常に重要なコミュニティである。歴史学の多くの分野において、本格的なネットワーク分析の導入がまさに発展途上にあることを踏まえれば、このコミュニティは今後さらに存在感を増していくことになるであろう。
3日間にわたるカンファレンスの初日には、4つのワークショップが用意された。Python による2 mode ネットワーク分析や ERGMs、社会ネットワーク分析導入など、実践的な内容のワークショップも用意される中で、とくに興味深かったのは Claire Lemercier による “From Historical Source to Network Data” というタイトルのワークショップであった[3]。内容はタイトルにある通り、歴史史料から実際にネットワークデータを構築する際の心構えや方法を論じるものであったが、その中で強調されていたのは、ネットワークデータ構築過程における「精読」と「史料批判」の重要性である。これらの重要性は歴史研究者にとっては自明であり、今更言われるまでもないと感じるかもしれないが、自然言語処理の応用や大規模データベースの利用によって、データ分析のみならず、データ構築過程までもが自動化されうる状況に鑑みれば、改めて強く意識される必要があるだろう。何がネットワーク分析に資する紐帯とみなされるべきなのか、そのような紐帯に関する記述はどの程度信頼できるのか、どのように様々な紐帯を抽象化し、類型化するか。これらの問題については、史料の特性やコンテキストを十分に踏まえたうえで、データ作成者が決定する必要がある[4]。その意味でやはり、ネットワークデータ構築に際して史料批判能力を持った研究者の存在は不可欠である。だが一方で、質的側面を捨象した機械的なデータ抽出によって、人手では不可能な大量のデータ構築が可能になる場合もあることは事実であり、そうしたデータが新たな知見をもたらす可能性も否定されるべきではない。それゆえ重要なのはやはり、用いるデータが誰によって、どのように作成されたのかを、分析・解釈に際して常に意識するというデジタル解釈学的な観点であろう[5]。このような思考を導くワークショップが初日に開催されたことは、2日目以降に行われた具体的な研究発表の導入としても意義があったように思う。
2日目以降は、いくつかのセッションに沿って研究発表が行われた。セッションの一覧を以下の表に示す。

表をみてもわかるように、セッションは多岐に及び、対象とする時代も古代から現代まで幅広い。一方で、地域についてみると、具体的な研究報告の多くは欧米圏に偏っており、非欧米圏を中心的に扱うものは “Biographies and Careers in China” のみである。各セッションにつき平均3件、全体では、ソフトウェア・デモを除いて計44件の研究報告が行われた。そのすべてに言及することはできないので、以下では筆者の関心に基づいて所感を述べることとしたい。
歴史ネットワーク分析と時間情報
まず今回のカンファレンスにおいては、ネットワークに関わる時間情報の取り扱いが重要な論点の一つであったという印象を受けた。例えば、18世紀末アメリカにおける商人ネットワークに関する報告を行った Louis Bissières は、それぞれ1785, 1786, 1787, 1791, 1795年における5つのネットワークを描出し、その間の時間的変遷を分析した[6]。分析を通して彼は、ネットワークの基本的な構造や顧客層の区分は5つのネットワークにおいて似通っていたとし、ある程度安定的な顧客との関係性が商人ネットワークを支えていたと結論付けた。Bissières がこのような時系列分析を行った背景には、歴史ネットワーク分析においてネットワークは静態的な構造とはみなせず、時間によって変化する動態的な構造であるとの思想が存在し[7]、このことは、彼の報告題目の中に “Taking Time Seriously” との一文が含まれていることからも明らかである。歴史ネットワーク分析において時間的変遷を十分に考慮する必要があるという点については、筆者も全く同意する。そのうえで問題になるのは、やはり具体的な手法であろう。
すでに述べたように Bissières は、年単位でネットワークを描き分けて分析を行った。これは彼が、年という時間幅が商人ネットワークの分析において最適であると判断したことを意味する。このような判断の是非については筆者の論じうるところではないが、少なくとも、このような時間幅の設定によって、結果として導かれるネットワークの変化の様相が変化しうる点は十分に認識されるべきだろう。つまり、解釈者のスケール設定によって解釈が異なりうるということである。
このようなスケール設定を巡っては、宗教改革期の社会ネットワークを扱った Ramona Roller 等の報告においても議論が交わされた[8]。彼女は、ネットワーク構造上の位置に関する指標を用いて各アクターの「役割 role」を抽出するモデルを提案しており、そのような「役割」の時間的変遷ももちろん考慮されている。Roller はネットワークの構造変化を捉えるに際して10年を1つの単位としているが、この点について、時間的スケール設定の妥当性を問う質問が為された。それに対し Roller は、10年より短いスパンでは、構造変化の傾向を捉えることができないと回答したが、これはあくまで彼女が扱う宗教改革期における改革者間の書簡ネットワークについて妥当するものであり、他の分野においては異なるスケール設定があり得ることも認めている。このことからも、時間的スケールの設定は、ネットワークの性質や分析の目的に応じて熟慮されるべきであり、成果の公表に際しては十分に説明されるべきであることがわかる。
ところで、歴史史料において言及される時間情報は、常に年月日等の絶対的時間情報であるとは限らず、場合によっては「X は Y の3週間前に起きた」「1800年頃」「X は Y の期間中に起きた」といった相対的で曖昧な情報でありうる。このような時間情報を可視化し、分析することを可能にするソフトウェアである Nodegoat が、ソフトウェア・デモにおいて紹介された。Nodegoat は、“Chronology Statement” という機能によって相対的時間情報の表現を可能にし、ChronoJSON という形式で記述されるため、機械的な分析や可視化が可能になる。このような相対的で曖昧な時間情報表現は歴史ネットワーク分析特有の問題と言え、今後も議論されるであろう。
バイオグラフィ研究とネットワーク分析
バイオグラフィ研究が歴史ネットワーク分析における大きなテーマの1つであることは、“Biographies and Careers in China” “Kinship and Genealogy” という2つのセッションが設けられたことからも窺われる。とくに “Biographies and Careers in China” は唯一、非欧米圏を主題としたセッションであり注目に値する。その中で、Christian Henriot と Cecile Armand は、中華民国期のエリート層ネットワークを、Biographical Dictionary of Republican China (BDRC) から抽出したデータによって構築した[9]。また Song Chen は、宋王朝時代の行政官僚が有した親族ネットワークを China Biographical Database (CBDB) から抽出し、1040–1049年と1210–1219年の構造を比較することで、この間に、都を中心とする中央集権的な構造から、地方分権的な構造への変化が生じたと結論付けた[10]。
ここでは、これらの研究についての中国史学的観点からの議論は行わないが、歴史ネットワーク分析の観点からみた場合、留意すべき点がある。それは、これらの研究がいずれも二次的なバイオグラフィ研究を土台にネットワークを構築している点である。これは、なにも上記の研究に限った話ではなく、バイオグラフィデータに基づくネットワーク分析一般に妥当する。例えば、ポスターセッションで古代ローマ共和政期の女性のネットワークを扱った Greg Gilles も、Digital Prosopography of the Roman Republic (DPRR) というデータベースに基づいてデータ構築を行っている[11]。
このような二次研究の利用は、当然ながら歴史ネットワーク研究のための有効な手段の一つである。大局的な構造や長期的な変化の傾向を捉えようとすれば、ある程度網羅的なネットワークデータを用いる必要があるが、それを個人で作成することは非常に困難である。この点で、信頼できる既存の研究は積極的に活用されるべきであるし、ネットワークとして再度分析することで、従来は見えていなかった構造が発見される可能性もある。その一方で、他者が構築し、すでにその解釈が含まれているデータを用いることになる以上、冒頭で述べたようなデジタル解釈学的な観点はここでも求められよう。すなわち、ネットワーク分析のデータソースとなる既存の研究がどのような史料に基づいて、どのような観点から、どのような形式で、誰によって為されたのかを把握し、説明可能にしておく必要がある。このことは、バイオグラフィやプロソポグラフィが、これまでの歴史研究による膨大なデータが蓄積されている分野であるからこそ、より一層求められることになるだろう。
結び
ここまで紹介したのは、様々なテーマを扱う研究報告のほんの一部にすぎないが、カンファレンスでは歴史ネットワーク分析に関して、じつに様々な角度から重要な報告、議論が交わされた。HNR が歴史学におけるネットワーク分析に特化したコミュニティであるだけあって、時間情報の扱いや史料解釈、曖昧性といった歴史ネットワーク分析特有の問題について、他のネットワーク関連の学会以上に本質的な議論が交わされていたという印象を受けた。冒頭で述べたように、歴史学分野におけるネットワーク分析はいまだ発展途上にあると言え、今後も HNR の活動を注視していきたいと思う。
イベントレポート「「2021年度アート・ドキュメンテーション学会年次大会」参加報告(前編)」
2021年6月19日(土)、20日(日)、2021年度アート・ドキュメンテーション学会年次大会がオンラインで開催された。開会挨拶によれば、会員・非会員あわせて330人ほどの申し込みがあり、おそらく過去最大の人数とのことであった。昨年に引き続きオンライン開催となったが、対面型イベントの良さを再認識するとともに、参加者に地域的な制限がなくなるというオンライン開催の利点も認識され、今後は両者のメリットを合わせたハイブリッド方式が使われるだろうという見通しが示された。今回は海外からも5名の参加者があり、日本の研究資源を対象とする国内外の組織の方々との連携を強化する必要性も説明された。
一日目は、日本の美術館コレクション検索をテーマとしたシンポジウム、及び野上紘子記念アート・ドキュメンテーション学会賞・推進賞講評と受賞者紹介が行われた。本稿では、シンポジウムの様子について報告する。
シンポジウムは、「美術館コレクション検索はどこへ向かうか―日本のプラットフォームの現状と将来像」をテーマとして行われた。はじめに、国立西洋美術館の川口雅子氏より趣旨説明があった。美術館コレクション検索をめぐって過去十数年の間に複数のアグリゲーターが林立しているが、各事業の位置づけや関係性についての情報が不足しており、美術館側に誤解や勘違いを生じさせている。たとえば文化遺産オンラインとジャパンサーチの連携には注目が集まっているが、現状では「国指定文化財等データベース」(文化庁)のデータがジャパンサーチにつながっているのみである。美術分野からもジャパンサーチへのデータ提供を行いたいと考えたが、つなぎ役(アグリゲーター)をたてて行う必要があるため、全国美術館会議が担うこととなった[1]。その枠組みから外れるものに関しては「Art Platform Japan」内のコンテンツの一つである全国美術館収蔵品サーチ「SHŪZŌ」が担う(「SHŪZŌ」については後の事例報告で詳しく説明があった)。将来的には「SHŪZŌ」からもジャパンサーチにつながるという展望も示された。
川口氏は、これまで総合的な検索プラットフォームの充実がなかなか進まなかった理由として、目的の共有が不十分だったのではないかということを挙げており、利用者の目的は横断検索そのものではなく何か理由があって情報を求めているということを指摘した。加えて提供側が作品情報へのアクセス向上によって何を得たいのか、そもそも美術館におけるコレクション・ドキュメンテーションとは何かといった、コレクション情報の本質から捉えなおす必要性が提起された。
趣旨説明の後、名古屋大学の栗田秀法氏による「美術館コレクション情報管理と共通検索可能なプラットフォームへの期待」というテーマの講演があり、まず文化庁による美術品資料目録作成の歴史と現状が説明された。次に、川口氏による問題提起を踏まえ、博物館・美術館の収蔵品管理方針の必要性や、キュレーターの仕事としての研究・学術的な目録作成が行われるべきであることが、日本博物館協会による博物館の原則や海外博物館の収蔵品管理方針を参照して示された。また、Musée de France(フランス博物館:文化省により認証された博物館の称号)の責務のひとつにはコレクションの目録を維持更新するという項目があり、ジョコンド・データベースという共同データベースが運営されていることが紹介された。
本講演では、作品情報やキーワードの充実はもちろん大事であるが、とりわけ価値付けの定まっていない現代美術に関しては、作家や作家を取り巻く情報の保存がなされることが重要であるとも指摘があった。講演中にも引用されていた梅棹忠夫の「博物館は既存の価値体系をおしつけるものではなく、(中略)未来の創造にむかわしめるための刺激と挑発の装置」[2]であるという考え方は、現代の美術館やデータベースに関しても共通するものであろう。既存の文化財や芸術作品のみならず、その枠からはみ出すような多様な方法によって表現される現代の芸術文化をいかにして残し、伝えていくかが問われていると感じた。
続いて事例1として、東京国立近代美術館の成相肇氏及び文化庁アートプラットフォーム事業事務局の手錢和加子氏より、「文化庁アートプラットフォーム事業〈全国美術館収蔵品サーチ〉」の取り組みに関する発表が行われた。
国内ですらどの美術館にどんな情報があるかが非常に分かりにくいという現状を解決すべく、文化庁アートプラットフォーム事業内の収蔵情報活用分科会が「SHŪZŌ」の構築を行っている。既存の目録やデータベースと比較した特徴として、「SHŪZŌ」は『全国美術館会議会員館 収蔵品目録総覧2014』(“目録の目録”)をもとに、各館に目録[3]を提供してもらい、データ入力などのデジタル化作業は事務局が担っている点が挙げられる。たとえば文化遺産オンラインは各館にデータを入力してもらう方式を採っているが、各館の尽力にもかかわらず基本的な情報へのアクセスすら容易ではない。そこで、「SHŪZŌ」では、こうした現状を改善するための一歩として、各館は既存の目録(可能であれば電子データも 注3参照)を事務局に提供するのみで、デジタル化や公開作業は事務局が行うことにしたという。
文化遺産オンラインやジャパンサーチとの関連については、文化遺産オンラインとは連携とデータ提供をしてもらう予定であるとのことであった。ジャパンサーチとの連携は未検討であるが、そもそもジャパンサーチに対応できている美術館は非常に少ないので、「SHŪZŌ」が各美術館にかわってジャパンサーチへデータ提供することを考えており、まずは「SHŪZŌ」登録館を増やしたいとのことであった。
こうした取り組みに対して、美術館関係者等から様々な反応が寄せられており、目録を見るためだけに遠方の館に行くという手間がなくなり助かるという好意的なもののほか、画像がないのは不便[4]という意見、公開によって収蔵品の所在がオープンになり貸出依頼が増加することについての意見などがあった。2021年度末までの到達目標として、収蔵品約12万件、美術館約150件、作家約2000件を掲げており、今後の追加公開や画像の追加などの情報拡充が期待される。
冒頭でも述べたように、「SHŪZŌ」の特徴は目録データのデジタル化にあたって美術館側の負担を少なくし、事務局側で作業を行っていることである。どのようなプラットフォームであっても、個々のデータ提供側と収集側の作業量のバランスに関しては、継続的な予算や人的資源の確保といった持続可能性の観点からも検討される必要があるだろう。
事例2では、東京富士美術館の鴨木年泰氏、国立国会図書館の徳原直子氏より、「ジャパンサーチのつなぎ役としての全国美術館会議の役割」として、美術館の収蔵品データベースとジャパンサーチの連携に関する事例が紹介された。鴨木氏は東京富士美術館の学芸員として、収蔵品データベースの管理を担当していることに加え、全国美術館会議の担当者としてジャパンサーチへのつなぎ役(アグリゲーター)でもある。他のアグリゲーターと異なり、データを取りまとめて直接ジャパンサーチへ提供するのではなく、美術館がジャパンサーチに参加したい場合に、会員館と運営側の国立国会図書館をつなぐ役割を果たしている。
徳原氏からは、ジャパンサーチ運営側の担当者として、ジャパンサーチの連携方法について紹介があった。ジャパンサーチでは、連携機関から登録・提供されたメタデータに「共通項目ラベル」を付与することによって、ジャパンサーチ利活用スキーマに変換し、分野横断の串刺し検索を実現している[5]。連携機関側の作業はデータベース基本情報の登録、メタデータの登録をまず行い、ジャパンサーチシステムから提示された共通項目ラベル候補を確認・修正し、個別項目ラベルの定義を行う、という流れになっており、合わせて二次利用条件の指定も必要である。
鴨木氏は、自館のデータベースをジャパンサーチと連携した美術館担当者の立場からの感想として、メタデータや利用条件表示などの意識が強まったことをまず挙げていた。徳原氏の報告にもあったように、ジャパンサーチへの連携の際にはこれらの項目を設定する必要がある。しかしながら、普段から標準化された利用条件表示やメタデータスキーマに沿ってデータベースを構築・公開している美術館ばかりではなく(むしろ少ないように思われる)、他のデータベースやプラットフォームとの連携も前提にしていないため、メタデータの整備や二次利用条件の設定を行うにあたっての検討があったと推察される。また、自館サイト上の収蔵品画像について、従来行っていた外部企業によるライセンス販売から無条件でのダウンロード・利用へと移行させており[6]、幅広い文脈の中で自館の所蔵作品が利用されること、他館の所蔵作品とあわせた作品群のなかで利用されることへの期待が高まっているとも述べられていた。美術館と利用者の双方にとって視野が広がるようなデータ利用や、それによって新たな価値が創造される可能性もあるだろう。
講演・事例報告の後、コメンテーターに愛知県美術館の副田一穂氏、金沢21世紀美術館石黒礼子氏を招き、質疑応答及び全体討論が行われた。副田氏からは、個々の機関で実際の作業を担当するのは開発者ではなく学芸員であり、使われている開発者向け情報や技術に対して疑問が湧いても、勉強して理解するには時間がかかることが指摘された。学芸員がすべて理解する必要はないが、何をやっているのかを分かるような講習などがあればよいと述べられていた。これからジャパンサーチへの参加を考えている館へのコメントとしては、労力対効果は低いが、自館でも展示機会が少ないような作品に対して貸出依頼が来るなど、思いがけない作品に光が当たることがあるという利点や、きたる東南海地震に備え、災害時のレスキュー台帳代わりになることが示された。
石黒氏からは、21世紀美術館のコレクション情報公開の取り組みについての説明があり、コレクション・カタログの刊行に先導されているが、現在は収蔵品管理システムが最新の情報基盤となるように新規収蔵作品の情報公開に取り組んでいるという事例が紹介された。美術館側からの意見として、公立館は自館のデータベース管理で手いっぱいであるが、今後どの機関やプラットフォームと連携するのが良いか展望が見えづらいこと、自館のウェブサイトへのリンク以外の方法で連携先で表示する場合には別途著作権処理が必要となるであろうこと、そして、所蔵館の負担がある中で連携を行う意義や目的について考えを深めたいということが述べられた。
全体討論・質疑応答では、館の担当者が変更になると、データベース連携の引継ぎが上手くいかない、途切れてしまうという問題が指摘され、実際に文化遺産オンラインとの連携ではそうした例が見られたという。個々の機関の仕事が増えると連携まで手が回らないという問題には、自館のウェブページやデータベースを更新する作業と同じように、もうひとつ連携をするということが現実的で、複数と連携するのはやや大変であるという意見もあった。他方で、そもそも自館内だけで精一杯で、外部への提供業務までできないという館もある。そのような悩みに対し、「SHŪZŌ」はデータをください、こちらで全部やりますという方法をとって軌道に乗りつつあること、しかしこのやり方では沢山データが集まるが、継続可能なのかという疑問も挙げられた。「SHŪZŌ」は恒常的な機関への運営移行を目指しており、安定した組織で持続的に運営していけるように計画・予定しているという。また、「SHŪZŌ」自体のシステムづくりに予算はかかったが、データ収集・入力にはそれほどお金がかかっておらず、継続できそうであるとも述べられた。
持続可能性に関しては、「SHŪZŌ」に対して各館が目録データを責任をもって出すことを基本とし、「SHŪZŌ」に提供したら終わりという考えでは困るという指摘や、「SHŪZŌ」で入力したデジタルデータを所蔵館へ戻すことはあるのかという質問があった。後者の質問に対する回答は、現状そのようなリクエストはないものの、デジタルデータの提供は可能であるということであった。
議論は大変盛り上がり、ここで紹介しきれなかったものもあるが、全体を通して見ると持続可能性や公益性といった内容が多かったように思われる。今後、さらに議論が深められることが期待される。
次号では、二日目の様子をお伝えしたい。
①神崎正英「ジャパンサーチ利活用スキーマの設計と応用」『デジタルアーカイブ学会誌』4-4 (2020): 342–347。
②中村覚「Cultural Japan の構築におけるジャパンサーチ利活用スキーマの活用」『デジタルアーカイブ学会誌』4-4 (2020): 348–351。
◆編集後記
本メールマガジンの刊行を開始して10年、毎月刊行を続け、ついに、120号を迎えることができました。 執筆者、編集関係者、読者の方々に支えられてここまでたどり着いたことに改めて深く感謝いたしております。 人文情報学/デジタル・ヒューマニティーズに関する国内外の話題を日本語で提供する場として、 若手・中堅の方々を中心に執筆をお願いしてきました。 始まった頃に若手だった人は中堅に、中堅だった人はベテランになり、 さらに新たな若手が担うようになってくださるという流れがこの10年の執筆者の陣容にも現れてきているように思います。 そのようにして、徐々に日本の人文情報学も厚くなってきました。 次の10年がどのような展開になるか、とても楽しみです。

そして、偶然にもこの月に、これまでの欧米関連の記事をまとめて再編集した『欧米圏デジタル・ヒューマニティーズの基礎知識』が刊行されることになりました。 495頁で2800円(税別)という比較的求めやすい価格になっております。 手元でパラパラと見てみたいときにはなかなか便利なものですので、 よかったらご覧になってみてください。(永崎研宣)