人文情報学月報第120号【前編】
目次
【前編】
- 《巻頭言》「デジタル・アーカイヴの手触り」
:慶應義塾ミュージアム・コモンズ/慶應義塾大学アート・センター - 《連載》「Digital Japanese Studies
寸見」第76回
「北米日本研究資料調整協議会が NCC Japanese Digital Image Gateway を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第37回
「ヒエログリフの機械翻訳を目指したゲーム会社・IT 企業・研究機関の国際共同プロジェクト Fabricius」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「ワークショップ「イスラーム研究用デジタルヒューマニティーズ:アラビア文字テキストのための TEI XML」(Islamicate Digital Humanities: TEI XML for Arabic-Script Texts)」
:岡山大学学術研究院社会文化科学学域 - イベントレポート「ワークショップ「Historical Networks — Réseaux Histriques — Historische Netzwerke conference 2021」」
:東京大学大学院人文社会系研究科 - イベントレポート「「2021年度アート・ドキュメンテーション学会年次大会」参加報告(前編)」
:東京大学大学院学際情報学府 - 編集後記
《巻頭言》「デジタル・アーカイヴの手触り」
2021年4月、慶應義塾大学三田キャンパスに、あたらしいミュージアム「慶應義塾ミュージアム・コモンズ(KeMCo)」が開館しました。慶應義塾には、統合型の大きなミュージアムはありません。これまで、研究・教育活動の中で蓄積されてきた様々な文化財や資料のコレクションは、その専門領域に応じて、学内の各所に収蔵され活用されてきました。KeMCo は、こうしたコレクションとその背後にある教育・研究活動を、自律性を保ちながらつなぎ、研究者や学生、卒業生、職員など大学に関わる人々が、オブジェクトを通じて交流する場所となるよう構想された機関です。
KeMCo の設置が決まった2018年から、筆者はこのような場所をデジタル空間にも構築し、現実の展示・収蔵などの活動と融合させることを試みるプロジェクト、通称「デジアナ融合プロジェクト」を担当しています。慶應義塾はこれまで、収蔵品を公開するウェブ・インターフェイスを大学としては持っていなかったので[1]、まずは大学のコレクションを広くカバーするいわゆる「デジタル・アーカイヴ」を構築することになりました。
このデジタル・アーカイヴは、「Keio Object Hub」[2]と名付けられ、KeMCo のグランド・オープンと同時に公開されましたが、開発に携わる中で「デジタル・アーカイヴの手触り」について考えるようになりました。これは、デジタル・アーカイヴにおいて、コレクションが所属している場所や、コレクションを守り活用する人々の個性をどのように表現すればよいのか?という問いです。冒頭で紹介したように、KeMCo は、オブジェクトを中心に人々が交流する場所であり、そこではオブジェクトとキャンパス、キャンパスと人の結びつきが重視されています。一方で、デジタル・アーカイヴの設計は、基本的には、オブジェクトの発見可能性を高め、その情報を正確に伝えること、またオブジェクト同士の関係を示すことに力点を置くため、ややもすると、オブジェクトが属する場所(キャンパス)や、関連する教育研究に携わる人々の活動が、後景として捨象されてしまいがちです。使いやすいデジタル・データを作るという観点でいうと、こういった情報はノイズともなり得るものかもしれませんが、すくなくとも KeMCo では、場所や周辺の人との結びつきを含んだオブジェクトの個性を、うまくデジタル・アーカイヴに取り込むことが重要だと考えています。
そのような観点でさまざまなデジタル・アーカイヴを見てゆくと、新たな発見が沢山あります。例えば、少なくないプラットフォームで採用されている、ギャラリーやオンライン展覧会などのキュレーションされたコンテンツは、そのプラットフォームをホストする場所(組織)や人々の個性を表現するための一つの方法でしょう。カリフォルニア大学サンタクルーズ校のキャンパスを舞台に展開した「Collective Museum」[3]は、キャンパス内の50の場所をミュージアムの作品として捉え直す一風変わったミュージアム・プロジェクトですが、そのアーカイヴ・サイトでは、作品のもつコンテクストが写真のフレーミングによってあぶり出されています。また、デジタル・アーカイヴから少し離れますが、メトロポリタン美術館の、展覧会の見所を豊富なビジュアルで紹介するコンテンツ「Meet the Primers」[4]は、短い動画を使用することによって、展覧会の息づかいをうまく表現しています。
Keio Object Hub では、このような例を踏まえつつ、「Behind the Hub」というまた違った仕掛けで、デジタル・アーカイヴの手触りを表現しようと試みています。Behind the Hub は、オブジェクトがアーカイヴに入ってゆく「過程」を捉えるコンテンツです。例えば、大学の片隅で見つかった正体不明のオブジェクトについて、教員や学生が調査をし、内容を同定しメタデータを作成する。撮影をしてデジタル・オブジェクトを作成し、レコードを作って Keio Object Hub に投入する。そのような活動を一つのプロジェクトとして Behind the Hub に登録し、進捗に合わせて更新していくことで、大学における(あるいはミュージアムにおける)オブジェクトのコレクションやデータベースといったものが、それぞれに固有の場所や人々と交流しながら、日々成長し変化することを表せるのではないかと考えています。
今回ご紹介した Keio Object Hub と Behind the Hub は、この夏に開催される KeMCo の展覧会「オブジェクト・リーディング:精読八景」(2021年8月16日~9月17日)で展示されます。暑い最中となりますが、お近くにいらした際にはぜひ足をお運びください。
デジタル・データの後ろには人がいて、場所がある。単純なことですが、データを使う人にもその繋がりを伝えられるように、デジタル・アーカイヴの手触りについて、これからも考え、実験していきたいと思います。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第76回
「北米日本研究資料調整協議会が NCC Japanese Digital Image Gateway を公開」
2021年7月12日、北米日本研究資料調整協議会(North American Coordinating Council on Japanese Library Resources; NCC)が NCC Japanese Digital Image Gateway を公開した[1][2][3]。NCC は、1991年に創設され、米国の連邦政府の一部門である日米友好基金から多くの援助を受けている非営利団体である。その目的としては、北米における日本研究上の資料に対する利用環境の向上があり、米国の有力日本研究学部・図書館を糾合して互助を図るための組織であると言える。日欧にも協力関係の団体はあり、サービス内容も必要次第で全世界での利活用を目指すものもある。
NCC には、すでに、「日本研究のための MLA アクセスガイド」[4]や、「日本研究デジタル資料(プロジェクト)」[5]など、日本研究のための情報収集が幅広くなされてきたところであったが、このたび、昨今の古典資料を中心としたデジタル画像の蓄積にともない、デジタル画像の情報源収集がなされたものであろう。関連しそうなものとして、「デジタル化理解と発見性プログラム」[6]では、このデータベースの中心的役割を担ったプリンストン大学東アジア図書館日本研究司書の野口契子氏も加わって、デジタルアーカイブの活用について議論が進んでいたようである[7]。
このデータベースは、前述の野口氏および NCC の加藤直子氏が中心になって集めたオンライン・デジタル画像資源を検索できるようにしたものである。各項目の更新履歴を見ると、2019年ごろから作業が進められたものであろうか。収集対象としては、日欧米の大学や機関のものとし、日英両言語で、題名(資料名あるいはコレクション名等)・資料の記述・キーワードが与えられている。おおむね原資料での記載にもとづき、データベース作成の際に翻訳されたものについては、その記載がある。収集単位は、あまりはっきりしない。「島根県里程図」[8]のようないわゆるコンテンツ単位のものもあれば(島根大学附属図書館デジタル・アーカイブや高野山アーカイブ収載コンテンツでそのようなものが見られた)、「新日本古典籍総合データベース」[9]のように、データベースも掲載されている。「宗田文庫図版資料」[10]のようにデータベース単位あるいはコレクション単位のものもあるが、これはコレクション単位のデータベースが取り上げられたものであろうか。
検索機能は、題名や記述の日英キーワード検索、カテゴリー検索がある。カテゴリーとして、IIIF で提供されているもの、クリエイティブ・コモンズライセンスの条件下で提供されているものというのがあるのが、いまどきである。なお、CC ライセンスというものは、あくまで固有のライセンスだから、オープン利用という観点で捉えられねば国会図書館デジタルライブラリーなどが扱えなくなってしまうが、それは本意ではないはずである。くわしい検索方法については利用案内[11]がある。デフォルトでは、各項目は日本語のローマ字の先頭のアルファベットによって区分されている。長いものはページが分かれている。あまり日本のデータベースにはない発想だと思う。「機能」[12]ページには、Cultural Japan をはじめとする大規模データベースの検索もできるとあるが、現時点では「利用案内」にも記載がなく、どういうことなのかよく分からなかった。ないままでよいとは思う。
日本研究のためのデジタル資料ガイドというと、稿者が編纂初期にかかわった人間文化研究機構の国際リンク集[13]や、国立国会図書館のリンク集[14]、同館の「文化・学術機関におけるデジタルアーカイブ等の運営に関する調査研究」[15]などがあるが、アップデートがされているかといったことや、解説の充実度という点であたらしいガイドへの需要があったと言えるだろう。本ガイドでも参照されているジャパン・サーチ[16]や Cultural Japan[17]も、コレクションの紹介としての機能はあまり持っていないし、たいへんユニークなデータベースであると思う。英語の部分はそう多くないし、検索機能もシンプルで、英語が苦手な方にとっても有用なデータベースだと思う。項目収集の方針など、もうすこし明らかであればなおよくなるのではないかと思われた。
なお、いささかバグがあるのはご愛敬であろうか。気づいたところでは、検索結果を出していちどなにかコンテンツへのリンクを開いてしまうと、ページネーションが無効化してしまう不備がある(URL が書き換えられてしまう)。なお、稿者のウェブブラウジング環境は Mozilla Firefox であるが、ねんのため Google Chrome で閲覧したところ再現しなかった(からよいというものではない)。
あれこれ申し上げたが、解題付きにせよ、なしにせよ、デジタルアーカイブ・データベースというのは、貴重な存在である。無理をなさらず、サステナブルに続けていただければたいへん素晴らしいことと思う。
CDDP Video Series - Comprehensive Digitization and Discoverability Program - LibGuides at North American Coordinating Council on Japanese Library Resources https://guides.nccjapan.org/cddp/video-series.
このサイトは連載第5回で取り上げている(拙稿「英語による学術情報発信:人間文化研究機構の English Resource Guide for Japanese Studies and Humanities in Japan をもとに」『人文情報学月報』49、2015年8月)。なお、稿者がかかわったという記載はいつの間にかなくなっている。ほとんど稿者の草したままで、昨今のデジタルアーカイブの隆盛に対応もできていない。また、当初 CC ライセンスで提供されたものがいつの間にかそうでなくなっている点も、おおいに残念である。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第37回
「ヒエログリフの機械翻訳を目指したゲーム会社・IT 企業・研究機関の国際共同プロジェクト Fabricius」
アサシン クリードと The Hieroglyphics Initiative
「アサシン クリード」(Assassin’s Creed)[1]という Ubisoft が開発・発売しているオープンワールド型のアドベンチャーゲームのシリーズがある。これは、歴史上の様々な時代・地域を舞台とするゲームであり、史実にフィクションを織り交ぜながら、ストーリーが展開していく。このゲームの歴史的な時代・地域の描写は、脚色された部分も多いものの、スタッフは、可能な限り再現しようとしている。例えば、2019年4月15日夜、パリのノートルダム大聖堂で火事が起き、尖塔が焼失するなどしたが、Ubisoft は、過去のアサシン クリード作品でノートルダム大聖堂の3Dモデルを登場させるために測量した数多くのデータを再建のために提供すると公表したことが大変話題となった[2]。
Ubisoft は、2017年10月27日に発売された「アサシン クリード オリジンズ」[3]で、ローマの属州となる前のプトレマイオス朝エジプトを舞台とするゲームを作り上げた。このゲームは、アサシンクリードシリーズの10番目の作品で、Windows、Play Station 4、Xbox One でプレイすることができ、全世界で1000万本以上の売り上げを記録した。数々のゲーム関連の賞にノミネートされ、Visual Effects Society Awards 2018では、Outstanding Visual Effects in a Real-Time Project 部門の勝者となった[4]。このゲームでは、エジプト学者の目からは奇妙に映るような誇張されたビジュアルなども散見されるものの、できる限り歴史的な正確さを追求するためスタッフはエジプト学者に何度も協力を仰ぎ、実際にエジプト学者が監修した部分も多いそうである。Ubisoft は、ゲーム本編とは別に、古代エジプトと古代ギリシアの歴史を学べる PC 教材である Discovery Tour も作成している[5]。
このゲームは、エジプト西部砂漠にあるシーワのオアシスにいたメジャイ(ファラオの守護戦士)である主人公バエクとその妻アヤを操作して、プトレマイオス朝が支配するエジプトを操作しようと暗躍する仮面の男たちの集団「古き結社」と戦っていく物語である。ことの発端は、紀元前48年にバエクが息子のケムと一緒に仮面の男にアメン神殿に拉致されてしまうことである。その際に、ケムが死んでしまったため、バエクとアヤは「古き結社」に復讐していく。その過程で、王位を狙うクレオパトラ(後のクレオパトラ7世)やエジプトに迫ってくるユリウス・カエサル率いるローマなどとの政治の駆け引きに巻き込まれていく。このゲームは、「古き結社」や、このシリーズで共通するアサシン教団などフィクションの部分と当時のプトレマイオス朝エジプトの史実を上手い具合にブレンドしたストーリー構成になっている。
さて、このゲームの制作をきっかけとして、Ubisoft は、エジプト学の本格的な研究に介入すべくヒエログリフで書かれた中エジプト語の機械翻訳の開発を目指す The Hieroglyphics Initiative[6]を2017年9月27日に大英博物館で発足させた。そして、2018年11月の Google Next London で、ヒエログリフの翻訳に機械学習が活用できること、そして、より多くのデータを収集してより良い機械学習モデルを作成するための方法とツールを開発したことが発表された。
このプロジェクトには、ベルリン・ブランデンブルク学術アカデミー、ザクセン学術アカデミー、アメリカの、エジプト学研究で著名なブラウン大学、ハーバード大学、カナダのケベック大学モントリオール校、そしてオーストラリアのマッコーリー大学などの学術機関が協力した。特に、ベルリン・ブランデンブルク学術アカデミーは、世界最大のエジプト語の辞書とエジプト語のタグ付きコーパスを有する Thesaurus Linguae Aegyptiae[7]のデータを提供した。
Fabricius と Google
2019年には、Google Arts & Culture[8]と Google Cloud[9]およびデジタルプラットフォームを手がける psycle[10]と共同開発が始まり、The Hieroglyphics Initiative で作成された諸ツールが全て Google プラットフォームに移行された。この諸ツールは一括りにして Fabricius と命名され、オープンソースでその翻訳ツールや教育ツールが公開された[11]。このプロジェクトの説明には、「この実験は、機械学習を利用して古代言語の翻訳の効率を高め、学術研究の新たな道を開く可能性を探るものです」[12]とある。
Fabricius は、ヒエログリフの基礎を覚えるアプリである Learn、ヒエログリフを友達などに送ることができるアプリ Play、そしてヒエログリフが写っている写真をアップロードしてそれを読み取り、自動翻訳する Work に分かれている。言語は今のところ英語版とアラビア語版がある。
Learn は、提示されたヒエログリフをなぞっていき、完了後はそのなぞりの評点や文字の説明が与えられるのを繰り返すのが第一ステップである。その後、一瞬表示された文字を記憶を頼りに再現する課題、一部分がかけている文字を復元させる課題、似た文字から壁に彫られている文字を当てる課題、読み順を当てる課題が続き、最後は、ツタンカーメン王の王名の意味の翻訳の部分を並べ替える課題が課される。それぞれの課題の間に Key fact として、ヒエログリフには音を表す文字、語を表す文字、意味を表す文字があることや、読む順番、そしてエジプト学者ガーディナーの付したヒエログリフの番号であるガーディナー番号についての説明がある。子どもでも楽しめるように、若い考古学者が、古代エジプトの墓の調査をしており、墓に刻まれたヒエログリフを研究するという体裁になっている。
Play は、ヒエログリフを絵文字代わりにしてメッセージを送るアプリである。ヒエログリフには音を表す表音文字、語を表す表語文字、語のカテゴリを表す限定符(決定符)の3つの文字種に分かれるが、意味を表すことができる限定符や表語文字よりも音だけを表す表音文字の使用の方が圧倒的に多い。ヒエログリフを絵文字として用いるのは、学習者にヒエログリフは全て表意文字であるかのような誤った印象を与えてしまいかねないので注意が必要である。
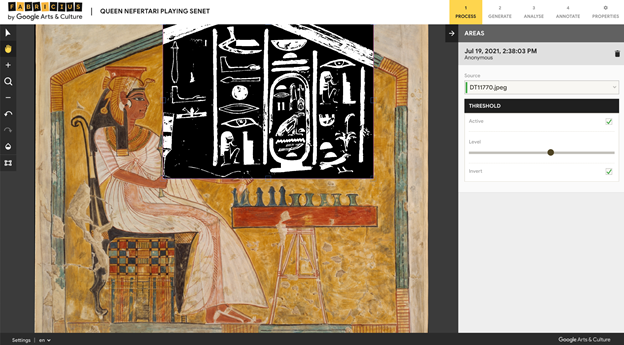
Work は、Fabricius の核であり、ヒエログリフの自動認識、そして自動翻訳を提供するツールである。メトロポリタン美術館のウェブサイトで提供されているパブリックドメインの、ヒエログリフが描かれている王妃ネフェルタリのステラ[13]を読み込ませてみた。最初は、刻文を白黒にバイナライズしなければならないようである。白黒反転もできるが、黒背景の方が、後の読み込みがよくできるようであった(図1)。その次の工程では、ヒエログリフの輪郭のみを残すようにする。この工程が非常に難しく、ネフェルタリのステラでは、綺麗に全ての輪郭のみを残すようにすることは困難だったが、いくつかの文字ではほぼ完璧に近い状態で輪郭だけを残せた。次が、機械による文字認識である。輪郭を完璧に捉えることのできた文字もいくつかあったが、ほぼ全ての文字で文字認識が失敗した(図2)。そのため、エラーを全て手で修正する必要があった。前の工程のやり方が悪かったのか、このステラに書かれている文字は刻文ではなかったのが原因なのか、わからないが、壁に刻まれたヒエログリフ文を用いても、文字の自動認識はほとんど手直しをしなければならないほどであった。文字認識の精度が上がっていくことを期待している。
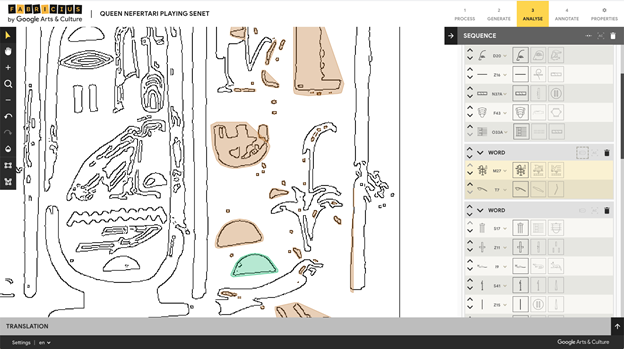
最後に、目玉の機械翻訳であるが、まだその機能は搭載されていないようである。しかし、このプロジェクトが進み、大量のデータを AI に学習させた時、より精度の高いヒエログリフの機械認識・機械翻訳ができるのかもしれない。このプロジェクトの今後の発展を見るのが楽しみである。